# Глава 15.6 Указатели на указатели. Ссылки на указатели
В C++ нельзя заводить [ссылки на ссылки.](/courses/cpp/chapters/cpp_chapter_0142/#block-reference-collapsing) А вот указатели на указатели — можно.
## Указатели на указатели
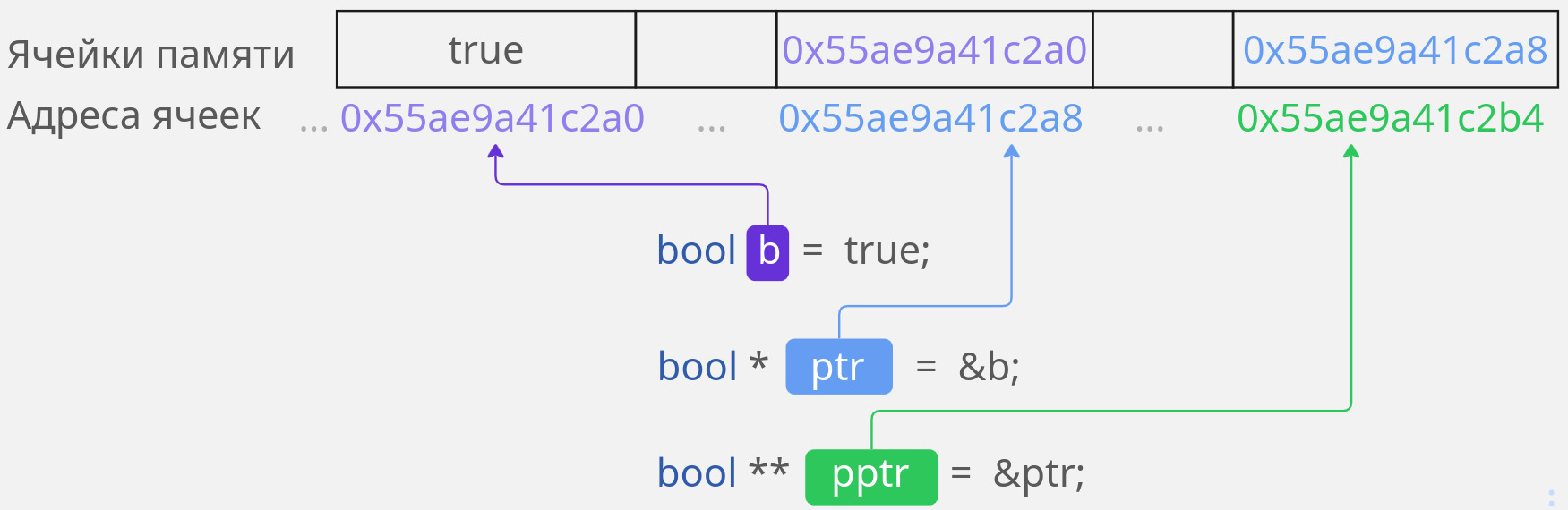
Указатель — это переменная, которая хранит адрес другой переменной. А указатель на указатель, получается, хранит адрес не просто какой-то переменной, а указателя.
```cpp {.example_for_playground .example_for_playground_001}
bool b = true; // Переменная
bool * ptr = &b; // Указатель
bool ** pptr = &ptr; // Указатель на указатель
// Разыменовываем pptr и получаем адрес, хранящийся в ptr
std::println("{}", static_cast<void *>(*pptr));
// Получаем значение b
std::println("{}", **pptr);
```
```
0x7ffeeec961b7
true
```
 {.illustration}
Указатель на указатель называют **двойным указателем.** Могут быть и указатели с любым другим уровнем косвенности. Например, указатель на указатель на указатель `T *** p`. Но на практике такие чудеса попадаются редко.
Количество звёздочек `*` в объявлении определяет уровень косвенности:
```cpp {.example_for_playground .example_for_playground_002}
int x = 8;
int * a = &x; // Указатель
int ** b = &a; // Двойной указатель
int *** c = &b; // Тройной
std::println("val: {}. x addr: {}", *a, static_cast<void *>(&x));
std::println("a value (x addr): {}", static_cast<void *>(a));
std::println("b value (a addr): {}", static_cast<void *>(b));
std::println("c value (b addr): {}", static_cast<void *>(c));
```
Основных сценариев применения указателей на указатели всего три:
- Работа с динамическими двумерными массивами (матрицами).
- Изменение указателя внутри функции.
- Взаимодействие с сишными интерфейсами.
## Динамические двумерные массивы
Двумерный массив — это массив указателей, каждый из которых «смотрит» на массив. При работе с таким массивом нужно соблюдать логичные правила:
- Выделять память сначала для внешнего массива, а потом для внутренних.
- Освобождать память в обратном порядке: сначала для внутренних массивов, затем — для внешнего.
Вот как это выглядит:
```cpp {.example_for_playground .example_for_playground_003}
std::size_t rows = 3;
std::size_t cols = 4;
// Аллоцируем массив указателей
int ** matrix = new int*[rows];
// В каждой ячейке выделяем массив чисел
for (std::size_t i = 0; i < rows; ++i)
matrix[i] = new int[cols];
// Работаем с массивом
for (std::size_t i = 0; i < rows; ++i)
{
for (std::size_t j = 0; j < cols; ++j)
{
matrix[i][j] = i + j; // Пишем
std::print("{} ", matrix[i][j]); // Читаем
}
std::println();
}
// Освобождаем память в обратном порядке
// Сначала освобождаем внутренние массивы
for (std::size_t i = 0; i < rows; ++i)
delete[] matrix[i];
// После этого освобождаем массив указателей
delete[] matrix;
```
```
0 1 2 3
1 2 3 4
2 3 4 5
```
Применение двойных указателей для создания матриц отлично подходит для учебных задач. Но в реальной разработке так практически не делают.
Во-первых, этот подход не дружелюбен к кешу: данные распределены по нескольким массивам. Массивы `matrix[i]` и `matrix[i + 1]` могут храниться в совершенно разных участках памяти! А значит, у процессора не получится эффективно кешировать элементы матрицы. Чтобы ускорить обращения к массиву, данные нужно держать единым блоком. Для этого вместо матрицы заводится одномерный массив длиной `rows * cols`, и в нём применяется арифметика индексов. Вместо записи `[i][j]` используется формула `index = i * cols + j`.
Во-вторых, выделять и освобождать ресурсы по двойному указателю — неудобно. Ошибку совершить ещё проще, чем при работе с обычным указателем. Поэтому используйте более современную и безопасную альтернативу: вектор векторов.
```cpp
std::vector<std::vector<int>> matrix(rows, std::vector<int>(cols));
```
В отличие от одномерного массива, такой подход тоже не дружелюбен к кешу: векторы `matrix[i]` и `matrix[i + 1]` могут располагаться в разных участках памяти. И всё же для большинства задач вектор векторов вполне подходит.
Что выведет этот код? {.task_text}
В случае ошибки компиляции напишите `err`. В случае неопределённого поведения напишите `ub`. {.task_text}
```cpp {.example_for_playground .example_for_playground_004}
std::size_t rows = 2;
std::size_t cols = rows;
int** matrix = new int*[rows];
for (std::size_t i = 0; i < rows; ++i)
matrix[i] = new int[cols];
matrix[0][0] = 1;
matrix[0][1] = 2;
matrix[1][0] = 3;
matrix[1][1] = 4;
int * ptr = matrix[0];
// Арифметика указателей ;)
std::println("{} {}", *(ptr + 1), *(ptr + 2));
```
```consoleoutput {.task_source #cpp_chapter_0156_task_0010}
```
Указатели `matrix[0]` и `matrix[1]` смотрят на два независимых массива, которые могут находиться в совершенно разных областях динамической памяти. Между ними могут быть расположены любые данные. Поэтому `*(ptr + 2)` — это выход за границы массива `matrix[0]`, состоящего из двух элементов. {.task_hint}
```cpp {.task_answer}
ub
```
## Двойные указатели и безопасное выделение памяти
Представьте, что вы пишете обёртку для сишной библиотеки обработки сигналов. Библиотека выдаёт данные по кускам, сегментами. И вы хотите завести RAII-класс, который склеивает эти сегменты в двумерный массив:
```cpp
class JaggedBuffer {
public:
// Конструктор принимает количество сегментов и массив длин сегментов.
// Он аллоцирует подо всё это память
JaggedBuffer(std::size_t row_count, const std::size_t * col_sizes);
// Освобождает всю память
~JaggedBuffer();
// Записывает сегмент по индексу
void set_segment(std::size_t index, const int * segment);
// Освобождает память из-под сегмента
void clear_segment(std::size_t index);
// Ещё какие-то полезные методы для обработки данных
// ...
private:
// Массив сегментов
int ** data = nullptr;
// Длина массива data
int rows = 0;
};
```
В конструктор передаётся количество сегментов и их длины. Длины могут быть разными, поэтому класс называется не просто `Buffer`, а `JaggedBufer`.
Давайте напишем наивную реализацию конструктора:
```cpp
JaggedBuffer::JaggedBuffer(std::size_t row_count, const std::size_t * col_sizes)
: rows(row_count)
{
if (rows == 0)
return;
data = new int*[rows];
for (std::size_t i = 0; i < rows; ++i)
data[i] = new int[col_sizes[i]];
}
```
У этой реализации есть фатальный недостаток: она приводит к утечке. Что будет, если на очередной итерации цикла не удастся выделить память под сегмент?
1. Конструктор бросит исключение `std::bad_alloc`.
2. Конструирование объекта класса `JaggedBuffer` прервётся.
3. А значит, для него при раскрутке стека не вызовется деструктор, освобождающий память.
4. Произойдёт утечка памяти, выделенной под массив `data` и под массивы сегментов.
Давайте сделаем конструктор безопасным:
```cpp
JaggedBuffer::JaggedBuffer(std::size_t row_count, const int * col_sizes)
: rows(row_count)
{
if (rows == 0)
return;
data = new int*[rows];
// Зануляем указатели, чтобы в любой момент
// безопасно вызвать для них delete
std::fill(data, data + rows, nullptr);
// Оборачиваем попытку аллокации в try-catch
try
{
for (std::size_t i = 0; i < rows; ++i)
data[i] = new int[col_sizes[i]];
}
catch (const std::bad_alloc & e)
{
// Вручную вызываем деструктор, чтобы освободить
// то, что успели выделить
~JaggedBuffer();
// Снова кидаем то же исключение `e`
throw;
}
}
```
Обратите внимание на зануление указателей на сегменты. Это необходимо, чтобы в любой момент времени можно было удалить сегменты, на которые ссылаются указатели `data[i]`.
В этом коде есть две интересные детали, с которыми вы раньше не сталкивались:
- Ручной вызов деструктора `~JaggedBuffer`. Вообще деструктор срабатывает автоматически, но только для полноценных объектов класса. А мы пишем код конструктора, то есть находимся на этапе, когда объекта ещё нет.
- Использование выражения [throw](https://en.cppreference.com/w/cpp/language/throw.html) без создания объекта исключения. Вместо записи `throw T{};` мы использовали просто `throw;`. Это нужно, чтобы передать уже перехваченное исключение `e` следующему обработчику.
Имеется сишная библиотека для гарантированной доставки данных по сети. Она позволяет открыть канал и получать из него данные сегментами разной длины. Интерфейс библиотеки состоит из функций для инициализации получения данных, завершения получения, доступа к сегментам и определения, сколько сегментов осталось не полученными. {.task_text}
Напишите класс — RAII-обёртку над этой библиотекой. Если потребуется, вы можете добавить в него приватные методы и поля, а также создавать свободные функции. {.task_text}
```cpp {.task_source #cpp_chapter_0156_task_0020}
// Интерфейс сишной библиотеки
/* Инициализирует дескриптор и возвращает 0 в случае успеха либо отрицательный
код ошибки в противном случае. Код ошибки err_no_memory означает, что не удалось
выделить память для дескриптора.
[in] addr - адрес источника данных,
[in] sgm_size - максимальный размер сегмента,
[out] pdesc - дескриптор канала данных. */
int open_recv(const char * addr, size_t sgm_size, recv_desc_t * pdesc);
/* Завершает получение данных и закрывает дескриптор канала данных.
[in/out] pdesc - валидный дескриптор канала данных. */
void close_recv(recv_desc_t * pdesc);
/* Возвращает ожидаемое количество сегментов: общее количество после открытия
и 0 — когда все сегменты получены.
[in] desc - валидный дескриптор канала данных. */
size_t sgm_left(recv_desc_t desc);
/* Возвращает сегмент данных. Возвращает 0 в случае успеха и отрицательный
код ошибки в противном случае. Код ошибки err_wait_for_data означает, что
следует вызвать функцию повторно. Код ошибки err_insufficient_buffer
сигнализирует, что размер переданного буфера недостаточен, а в size возвращается
ожидаемый размер.
[in] desc - валидный дескриптор канала данных,
[out] idx - индекс сегмента,
[out] buf - буфер для сохранения сегмента,
[in/out] size - размер буфера на входе и реальный размер сегмента данных
на выходе. */
int recv_sgm(recv_desc_t desc, size_t * idx, void * buf, size_t * size);
// Объявление класса-обёртки
class SegmentReceiver {
public:
// Конструктор и методы выбрасывает std::bad_alloc при нехватке
// памяти и std::runtime_error в других случаях.
// Инициализирует канал данных и буфер для хранения сегментов.
SegmentReceiver(const std::string & address, std::size_t segment_size);
// Закрывает канал.
~SegmentReceiver();
// Получает очередной сегмент данных и сохраняет его во внутренний
// буфер. Возвращает количество полученных сегментов и
// общее количество сегментов.
std::pair<std::size_t, std::size_t> receive_segment();
// Объединяет сегменты и возвращает результат, если были получены
// все сегменты, в противном случае бросает исключение.
std::vector<std::uint8_t> merge_segments() const;
private:
// Дескриптор канала данных
recv_desc_t m_recv = nullptr;
// Массив сегментов
std::uint8_t ** m_segments = nullptr;
// Длины сегментов
std::size_t * m_sizes = nullptr;
// Количество сегментов
std::size_t m_total = 0;
};
// Ваш код: определение методов
```
Не забудьте сделать конструктор безопасным. {.task_hint}
```cpp {.task_answer}
class SegmentReceiver {
public:
SegmentReceiver(const std::string & address, std::size_t segment_size);
~SegmentReceiver();
std::pair<std::size_t, std::size_t> receive_segment();
std::vector<std::uint8_t> merge_segments() const;
private:
std::string address() const;
std::string unexpected_error(int err_code) const;
void allocate_segment(std::size_t index, std::size_t size);
std::size_t received_segment_count() const;
void clear();
recv_desc_t m_recv = nullptr;
std::uint8_t ** m_segments = nullptr;
std::size_t * m_sizes = nullptr;
std::size_t m_total = 0;
};
recv_desc_t make_receiver(const std::string& address, std::size_t segment_size)
{
recv_desc_t recv = nullptr;
int code = ::open_recv(address.c_str(), segment_size, &recv);
if (code == err_no_memory)
{
throw std::bad_alloc{};
}
else if (code < 0)
{
const std::string& msg = std::format(
"Failed to open channel by address {} with segment size {}. Error code: {}",
address, segment_size, code);
throw std::runtime_error{ msg };
}
return recv;
}
template <class I>
I * make_array(std::size_t count)
{
I* arr = new I[count];
std::fill(arr, arr + count, I{});
return arr;
}
SegmentReceiver::SegmentReceiver(const std::string& address, std::size_t segment_size)
{
try
{
m_recv = make_receiver(address, segment_size);
m_total = ::sgm_left(m_recv);
m_segments = make_array<std::uint8_t*>(m_total);
m_sizes = make_array<std::size_t>(m_total);
}
catch (...)
{
clear();
throw;
}
}
SegmentReceiver::~SegmentReceiver()
{
clear();
}
std::pair<std::size_t, std::size_t> SegmentReceiver::receive_segment()
{
std::size_t index = 0;
std::size_t size = 0;
int code = 0;
do
{
code = ::recv_sgm(m_recv, &index, nullptr, &size);
} while (code == err_wait_for_data);
if (code != err_insufficient_buffer)
throw std::runtime_error{ unexpected_error(code) };
allocate_segment(index, size);
code = ::recv_sgm(m_recv, &index, m_segments[index], &size);
if (code < 0)
throw std::runtime_error{ unexpected_error(code) };
m_sizes[index] = size;
return { received_segment_count(), m_total };
}
std::vector<std::uint8_t> SegmentReceiver::merge_segments() const
{
const std::size_t received_count = received_segment_count();
if (received_count != m_total)
{
const std::string& msg = std::format(
"Unable to compose data, not all segments were received. Received / total: {} / {}",
received_count, m_total);
throw std::runtime_error{ msg };
}
const std::size_t data_size = std::accumulate(m_sizes, m_sizes + m_total, 0ull);
std::vector<std::uint8_t> data(data_size);
std::size_t pos = 0;
for (std::size_t i = 0; i < m_total; ++i)
{
const std::uint8_t* segment = m_segments[i];
const std::size_t size = m_sizes[i];
std::copy(segment, segment + size, data.data() + pos);
pos += size;
}
return data;
}
std::string SegmentReceiver::address() const
{
const char* addr = ::recv_addr(m_recv);
return addr != nullptr ? std::string{ addr } : std::string("unknown");
}
std::string SegmentReceiver::unexpected_error(int err_code) const
{
return std::format(
"Can't receive data from '{}' due to unexpected error {}.", address(), err_code);
}
void SegmentReceiver::allocate_segment(std::size_t index, std::size_t size)
{
if (m_sizes[index] < size)
{
delete[] m_segments[index];
m_segments[index] = new std::uint8_t[size];
m_sizes[index] = size;
}
}
std::size_t SegmentReceiver::received_segment_count() const
{
return m_total - ::sgm_left(m_recv);
}
void SegmentReceiver::clear()
{
if (m_segments != nullptr)
{
for (std::uint8_t** cur = m_segments, **end = cur + m_total; cur != end; ++cur)
delete[] * cur;
delete[] m_segments;
}
delete[] m_sizes;
::close_recv(&m_recv);
}
```
## Функция main() с аргументами командной строки
Функция `main()` — это точка входа в программу. И до сих пор мы пользовались её простой формой без параметров:
```cpp
int main()
{
// ...
}
```
Но как быть, если нужно передать программе аргументы командной строки? На помощь приходит параметризованная форма `main()`:
```cpp
int main(int argc, char ** argv);
```
Имена параметров могут быть любыми, но принятыми считаются `argc` и `argv`.
- `argc` (argument count) — количество переданных программе аргументов с учётом имени самой программы.
- `argv` (argument vector) — массив указателей на [сишные строки](/courses/cpp/chapters/cpp_chapter_0155/#block-c-string) с аргументами. Первым аргументом ОС подставляет указатель на строку с именем программы.
Допустим, бинарь называется `copy`, и мы запустили его из консоли, дополнительно передав опции:
```bash
./build/bin/copy --from conf.json --to conf_backup.json
```
Выведем содержимое `argc` и `argv`:
```cpp {.example_for_playground .example_for_playground_005}
int main(int argc, char ** argv)
{
std::println("Arg count: {}", argc);
for (int i = 0; i < argc; ++i)
std::println("{}: {}", i, argv[i]);
}
```
```
Arg count: 5
0: ./build/bin/copy
1: --from
2: conf.json
3: --to
4: conf_backup.json
```
Аргументы разделяются пробелами. Если в самом тексте аргумента есть пробел, то его берут в кавычки:
```bash
./build/bin/copy --from conf.json --to "./useful data/conf_backup.json"
```
```
Arg count: 5
0: ./build/bin/copy
1: --from
2: conf.json
3: --to
4: ./useful data/conf_backup.json
```
Популярна альтернативная форма записи второго аргумента: `char * argv[]` вместо `char ** argv`.
```cpp
int main(int argc, char * argv[]);
```
С точки зрения компилятора разницы между этими вариантами записи нет. Потому что при передаче сишного массива в функцию происходит [низведение массива:](/courses/cpp/chapters/cpp_chapter_0132/#block-array-to-pointer-decay) он приводится к указателю на нулевой элемент. Зато с точки зрения разработчика запись `char* argv[]` более «говорящая»: сразу понятно, что `argv` — это массив указателей на символы `char`.
Итак, аргументы попадают в `main()` в качестве сишных строк. А если нужно передать программе число?
Для приведения строки к числовым типам есть функции:
- [std::stoi()](https://en.cppreference.com/w/cpp/string/basic_string/stol) принимает строку и возвращает `int`.
- [std::stod()](https://en.cppreference.com/w/cpp/string/basic_string/stof.html) принимает строку и возвращает `double`.
Обе функции кидают исключения `std::invalid_argument` (если преобразование невозможно) и `std::out_of_range` (если результирующее число выходит за пределы диапазона типа). Чтобы получить из строки число типа `long long`, `float`, `long double` или любого другого, используйте функции с соответствующими суффиксами: `std::stoll()` и другие.
Программа умеет принимать аргументы двух типов: именованные вида `--key=val` и позиционные вида `val`. Любые аргументы опциональны. Позиционные могут идти только после того, как закончились именованные. Именованные начинаются с `--` и в них после знака `=` указывается значение. {.task_text}
Вам нужно написать функцию `parse_args()`, которая получает количество аргументов и их массив. Она возвращает структуру `Args`, в которую эти аргументы разобраны. {.task_text}
Например, программа запущена так: `./run --filelimit=10 --ignore-case=true /tmp/backup`. Здесь `./run` — нулевой аргумент, и он не должен попасть в структуру. В поле `keyword` структуры окажется две пары ключ-значение: `{"filelimit", "10"}` и `{"ignore-case", "true"}`. А в поле `positional` — единственное значение `"/tmp/backup"`.
```cpp {.task_source #cpp_chapter_0156_task_0030}
struct Args
{
std::unordered_map<std::string, std::string> keyword;
std::vector<std::string> positional;
};
Args parse_args(int argc, char * argv[])
{
}
```
У строки `std::string` есть конструктор от `char *` и методы `starts_with()`, `find()` и `substr()`. {.task_hint}
```cpp {.task_answer}
struct Args
{
std::unordered_map<std::string, std::string> keyword;
std::vector<std::string> positional;
};
Args parse_args(int argc, char * argv[])
{
Args args;
for (std::size_t i = 1; i < argc; ++i) // Пропускаем имя программы
{
const std::string arg{argv[i]};
if (arg.starts_with("--")) // Именованный аргумент
{
if (std::size_t pos = arg.find('='); pos != std::string::npos)
args.keyword[arg.substr(2, pos - 2)] = arg.substr(pos + 1);
}
else // Позиционный аргумент
{
args.positional.push_back(arg);
}
}
return args;
}
```
## Изменение указателя внутри функции
Допустим, мы хотим занулить указатель, вызвав для него `set_to_null()`:
```cpp {.example_for_playground .example_for_playground_006}
void set_to_null(int * p)
{
p = nullptr;
std::println("p == nullptr in function: {}",
p == nullptr);
}
int main()
{
int val = 5;
int * p_val = &val;
set_to_null(p_val);
std::println("p_val == nullptr in main: {}",
p_val == nullptr);
}
```
```
p == nullptr in function: true
p_val == nullptr in main: false
```
Почему ничего не получилось? Как вы помните, есть два способа передачи параметров в функцию:
- По значению. При этом в функцию попадает копия аргумента, и функция не может изменить исходную переменную.
- По ссылке. Иногда такой способ называют **по адресу.** В функцию попадает адрес исходной переменной, и функция может её изменить.
Мы передали переменную `p_val` _по значению,_ и в функцию попала _её копия._ Сама по себе переменная является указателем и хранит адрес. Внутри функции адрес был занулён, но это изменение коснулось только копии. А в оригинальной переменной продолжил лежать адрес `val`.
Как же изменять указатель внутри функции? Способов два. Вы можете передавать указатель:
- [По ссылке](/courses/cpp/chapters/cpp_chapter_0141/#block-func) `int *& p`.
- По указателю `int ** p`, то есть как двойной указатель.
### Передача указателя по ссылке
`T *&` — это ссылка `&` на указатель `*` на объект типа `T`.
Давайте исправим предыдущий пример и передадим указатель по ссылке:
```cpp {.example_for_playground .example_for_playground_007}
void set_to_null(int *& p) // Поменяли тип `int *` на `int *&`
{
p = nullptr;
std::println("p == nullptr in function: {}",
p == nullptr);
}
int main()
{
int val = 5;
int * p_val = &val;
set_to_null(p_val);
std::println("p_val == nullptr in main: {}",
p_val == nullptr);
}
```
```
p == nullptr in function: true
p_val == nullptr in main: true
```
Единственное изменение, которое мы сделали в коде — это замена типа параметра с `int *` на `int *&`.
[Вспомните,](/courses/cpp/chapters/cpp_chapter_0141/#block-refs-under-the-hood) что такое ссылки под капотом. {.task_text}
Как вы считаете, допустим ли синтаксис `T &*` — указатель на ссылку? `Y/N` {.task_text}
```consoleoutput {.task_source #cpp_chapter_0156_task_0040}
```
Указатель должен хранить адрес некоей области памяти. Ссылка не является объектом в памяти в том же смысле, что и переменная. {.task_hint}
```cpp {.task_answer}
n
```
### Передача указателя по указателю
А теперь опробуем передачу по указателю:
```cpp {.example_for_playground .example_for_playground_008}
void set_to_null(int ** p) // Поменяли тип `int *` на `int **`
{
*p = nullptr; // Разыменовываем двойной указатель
std::println("p == nullptr in function: {}",
*p == nullptr);
}
int main()
{
int val = 5;
int * p_val = &val;
set_to_null(&p_val); // Передаём адрес указателя p_val
std::println("p_val == nullptr in main: {}",
p_val == nullptr);
}
```
```
p == nullptr in function: true
p_val == nullptr in main: true
```
При передаче двойного указателя изменений в коде уже три:
- `int **` вместо `int *` — замена типа параметра функции.
- `*p` вместо `p` — разыменовывание двойного указателя внутри функции для доступа к исходному.
- `&p_val` вместо `p_val` — передача в функцию не самого указателя, а его адреса.
Как видите, передача указателя по ссылке гораздо удобнее, чем по указателю.
----------
## Резюме
- Двойной указатель — это указатель на указатель `T **`.
- Двойные указатели нужны для:
- создания двумерных динамических массивов,
- изменения указателя внутри функции,
- взаимодействия с сишными интерфейсами.
- Более удобный способ изменения указателя внутри функции — передача его по ссылке `T *&`.
- У точки входа в программу `main()` есть перегрузка, принимающая количество аргументов командной строки и массив строк с самими аргументами.
Наша группа в telegram. Здесь можно задавать вопросы и общаться.
Задонатить. Если вам нравится курс, вы можете поддержать развитие площадки!