# Глава 14.1. Ссылки: знакомство
Вы уже [знаете,](/courses/cpp/chapters/cpp_chapter_0131/#block-alias) что в C++ для любого типа можно завести псевдоним. То есть определить новое имя и работать с ним вместо исходного типа. Точно так же можно поступить и с переменной: создать альтернативное имя и обращаться к переменной через него. Это имя и будет называться ссылкой.
## Что такое ссылка
[Ссылка](https://www.en.cppreference.com/w/cpp/language/reference.html) (reference) — это псевдоним для существующей переменной.
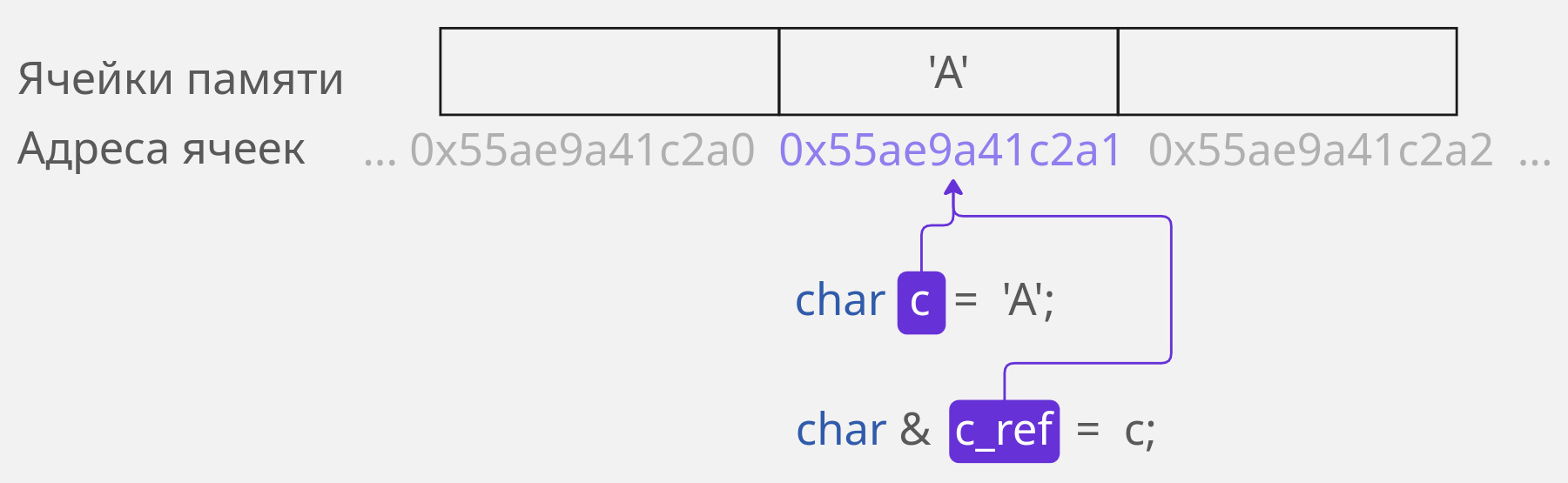
Чтобы объявить ссылку, между типом и именем переменной ставится символ амперсанда `&`. Он означает, что перед вами не обычный тип, а ссылочный. В данном примере у переменной `c_ref` тип `char &`: это ссылка на `char`.
```cpp {.example_for_playground .example_for_playground_001}
char c = 'A';
char & c_ref = c; // Ссылка
std::println("{}", c_ref);
```
```
A
```
Разработчику удобно думать про ссылки как про псевдонимы переменных. Но как выглядят ссылки с точки зрения компилятора? Это целиком и полностью зависит от реализации. Стандарт даже [не определяет,](https://timsong-cpp.github.io/cppwp/n4868/dcl.ref#4) выделяется ли под ссылку память. Как правило — нет, [не выделяется.](https://isocpp.org/wiki/faq/references#overview-refs) Каждая переменная живёт в своей области памяти: она связывается с конкретным адресом. И компилятор работает со ссылкой как с адресом исходной переменной.
 {.illustration}
## Работа со ссылками
Читать и изменять значение можно как через исходную переменную, так и через ссылку:
```cpp {.example_for_playground .example_for_playground_002}
std::size_t count = 1;
std::size_t & n = count;
std::println("count={} n={}", count, n);
++n;
std::println("count={} n={}", count, n);
count += 2;
std::println("count={} n={}", count, n);
```
```
count=1 n=1
count=2 n=2
count=4 n=4
```
Что выведется в консоль? {.task_text}
```cpp {.example_for_playground .example_for_playground_003}
unsigned char x = 255;
unsigned char & ref1 = x;
unsigned char & ref2 = x;
++ref1;
++ref2;
std::println("{} {} {}", x, ref1, ref2);
```
```consoleoutput {.task_source #cpp_chapter_0141_task_0010}
```
Тип `unsigned char` занимает 1 байт. Значит, 255 — это максимальное для него значение, и при его увеличении произойдёт беззнаковое переполнение. {.task_hint}
```cpp {.task_answer}
1 1 1
```
Расстановка пробелов вокруг символа `&` роли не играет. Все эти объявления считаются допустимыми:
```cpp
T& name;
T & name;
T &name;
```
Тип ссылки должен совпадать с типом переменной, на которую она указывает. При нарушении этого правила ваш код не скомпилируется:
```cpp {.example_for_playground .example_for_playground_004}
bool has_access = false;
std::string & ref = has_access;
```
```
main.cpp:7:19: error: non-const lvalue reference to type 'std::string' (aka 'basic_string<char>') cannot bind to a value of unrelated type 'bool'
7 | std::string & ref = has_access;
| ^ ~~~~~~~~~~
```
В момент создания ссылки её необходимо инициализировать. Не инициализированная ссылка приведёт к ошибке компиляции:
```cpp {.example_for_playground}
import std;
int main()
{
std::string & s;
}
```
```
main.cpp:5:19: error: declaration of reference variable 's' requires an initializer
5 | std::string & s;
| ^
```
Ссылка не может быть переназначена после инициализации. Оператор `=` для ссылки изменяет значение переменной, на которую она указывает, а не саму ссылку. Иными словами, все своё время жизни ссылка «смотрит» на один и тот же объект.
Что выведется в консоль? {.task_text}
```cpp {.example_for_playground .example_for_playground_005}
int a = 1;
int b = 5;
int & ref = a;
ref = b;
b = 8;
std::println("{} {} {}", a, ref, b);
```
```consoleoutput {.task_source #cpp_chapter_0141_task_0020}
```
В выражении `ref = b` значение `b` присваивается переменной, на которую указывает ссылка `ref`. {.task_hint}
```cpp {.task_answer}
5 5 8
```
Как вы считаете, можно ли завести ссылку на `void`? `y/n` {.task_text}
```consoleoutput {.task_source #cpp_chapter_0141_task_0030}
```
У типа `void` пустой набор значений, а ссылка должна указывать на полноценный объект. Поэтому стандарт [запрещает](https://timsong-cpp.github.io/cppwp/n4868/dcl.ref#1) ссылки на `void`. {.task_hint}
```cpp {.task_answer}
n
```
## Передача параметров по ссылке {#block-func}
По умолчанию функции принимают параметры по значению (by value): при вызове функции в неё вместо исходных переменных попадают _копии._ Убедимся в этом:
```cpp {.example_for_playground}
import std;
void sort(std::vector<int> v)
{
std::sort(v.begin(), v.end());
std::println("Inside function: {}", v);
}
int main()
{
std::vector data{5, 0, -1, 2};
std::println("Before calling sort(): {}", data);
sort(data);
std::println("After calling sort(): {}", data);
}
```
```
Before calling sort(): [5, 0, -1, 2]
Inside function: [-1, 0, 2, 5]
After calling sort(): [5, 0, -1, 2]
```
Копирование — это дорогая операция, особенно для тяжёлых объектов. Представьте, что в этом примере в функцию `sort()` передаётся массив из миллионов элементов. Он целиком будет скопирован! Так вот, предотвращение лишнего копирования — это наиболее частый сценарий использования ссылок.
Так заменим же передачу вектора по значению на передачу по ссылке (by reference). Для этого между типом и именем параметра функции добавим амперсанд:
```cpp
void sort(std::vector<int> & v);
```
Когда функция принимает аргумент по ссылке, компилятор связывает существующую переменную с новым именем — параметром функции. То есть заводит для неё псевдоним. И функция получает доступ к исходному объекту вместо копии:
```cpp {.example_for_playground}
import std;
void sort(std::vector<int> & v) // передаём v по ссылке
{
std::sort(v.begin(), v.end());
std::println("Inside function: {}", v);
}
int main()
{
std::vector data{5, 0, -1, 2};
std::println("Before calling sort(): {}", data);
sort(data);
std::println("After calling sort(): {}", data);
}
```
```
Before calling sort(): [5, 0, -1, 2]
Inside function: [-1, 0, 2, 5]
After calling sort(): [-1, 0, 2, 5]
```
Реализуйте функцию `rotate_clockwise()`, которая принимает по ссылке квадратную матрицу `m` и ничего не возвращает. Матрица — это вектор векторов с элементами типа `short`. {.task_text}
Функция поворачивает исходную матрицу на 90 градусов по часовой стрелке. В подсказке описан простой вариант реализации поворота. {.task_text}
Например, матрица `{{1, 2}, {3, 4}}` после вызова функции превратится в `{{3, 1}, {4, 2}}`: {.task_text}
```
// Исходная матрица
[
[1, 2]
[3, 4]
]
// Поворот на 90 градусов по часовой стрелке
[
[3, 1]
[4, 2]
]
```
```cpp {.task_source #cpp_chapter_0141_task_0040}
// Ваша реализация rotate_clockwise()
```
Сначала [поменяйте местами](https://en.cppreference.com/w/cpp/algorithm/swap.html) все элементы `m[i][j]` и `m[j][i]`. Это транспонирует матрицу, то есть превратит строки в столбцы, а столбцы — в строки. Затем [инвертируйте](https://cppreference.com/w/cpp/algorithm/reverse.html) порядок элементов в каждом ряду. {.task_hint}
```cpp {.task_answer}
void rotate_clockwise(std::vector<std::vector<short>> & m)
{
for (std::size_t i = 0; i < m.size(); ++i)
{
for (std::size_t j = i + 1; j < m.size(); ++j)
{
std::swap(m[i][j], m[j][i]);
}
}
for (std::size_t i = 0; i < m.size(); ++i)
std::reverse(m[i].begin(), m[i].end());
}
```
В стандартной библиотеке есть функция [std::swap()](https://en.cppreference.com/w/cpp/algorithm/swap.html), которая принимает два параметра и меняет местами их значения. Разумеется, для этого она принимает оба параметра по ссылке. Так выглядит её объявление:
```cpp
namespace std {
template<class T>
void swap(T & a, T & b);
// ...
}
```
Реализуйте собственную функцию `swap()`. Она принимает два параметра типа `double` и меняет их местами. {.task_text #block-swap}
Например, есть две переменные `x = 1.0` и `y = 5.0`. После вызова `swap(x, y)` в `x` должно лежать число `5.0`, а в `y` — число `1.0`. {.task_text}
```cpp {.task_source #cpp_chapter_0141_task_0050}
// Ваша реализация swap()
```
Функция должна принимать два параметра по ссылке. Чтобы поменять их местами, внутри функции вы можете завести дополнительную переменную. {.task_hint}
```cpp {.task_answer}
void swap(double & a, double & b)
{
double tmp = a;
a = b;
b = tmp;
}
```
## Использование ссылок в цикле range-for
Как вы помните, один из вариантов цикла `for` — это [цикл по диапазону](/courses/cpp/chapters/cpp_chapter_0042/#block-range-for) (range-for):
```cpp
for (item : range-initializer)
{
// ...
}
```
В таком цикле удобно перебирать элементы контейнеров:
```cpp {.example_for_playground .example_for_playground_006}
std::vector<std::string> available_bluetooth_devices = {
"TV 4562",
"Sonny's headset",
"jbl headphones"
};
for(std::string device: available_bluetooth_devices)
std::println("{}", device);
```
```
TV 4562
Sonny's headset
jbl headphones
```
Здесь на каждой итерации цикла в переменную `device` попадает _копия_ элемента контейнера `available_bluetooth_devices`. Как неэффективно! Чтобы избежать лишнего копирования, нужно всего лишь поменять тип переменной, через которую перебирается контейнер:
```cpp {.example_for_playground .example_for_playground_007}
for(std::string & device: available_bluetooth_devices)
std::println("{}", device);
```
Теперь `device` — это ссылка на строку. Мы избавились от копирования при итерировании по контейнеру. Кроме того, теперь мы можем по этой ссылке модифицировать сами элементы, а не их копии:
```cpp {.example_for_playground .example_for_playground_008}
for(std::string & device: available_bluetooth_devices)
device = "*****";
std::println("{}", available_bluetooth_devices);
```
```
["*****", "*****", "*****"]
```
Чтобы достичь схожего результата, до сих пор вам приходилось организовывать циклы с итераторами или циклы по индексам. Кстати, при обращении по индексу или по ключу используется [оператор](https://en.cppreference.com/w/cpp/container/vector/operator_at.html) `[]`. Он возвращает _ссылку_ на элемент контейнера. Именно за счёт этого синтаксис квадратных скобок позволяет работать с элементами контейнера, а не их копиями.
```cpp {.example_for_playground .example_for_playground_009}
available_bluetooth_devices[1] = "-"; // Присваиваем значение "-"
std::println("{}", available_bluetooth_devices);
```
Реализуйте функцию `lower()`, которая принимает вектор строк и переводит все строки в нижний регистр. {.task_text}
Например, строка `"ReFeRenCe"` в нижнем регистре будет выглядеть как `"reference"`. {.task_text}
Вам помогут: {.task_text}
- Функция [std::tolower()](https://en.cppreference.com/w/cpp/string/byte/tolower.html), которая переводит символ типа `unsigned char` в нижний регистр.
- Знание того, что `std::string` состоит из символов `char`, а не `unsigned char`.
- Явное приведение типов через [static_cast](https://en.cppreference.com/w/cpp/language/static_cast.html).
- Алгоритм [std::transform()](https://en.cppreference.com/w/cpp/algorithm/transform) для применения `std::tolower()` к каждому символу строки.
- Цикл `range-for` по ссылкам на элементы вектора.
```cpp {.task_source #cpp_chapter_0141_task_0060}
void lower(std::vector<std::string> & words)
{
}
```
Заведите вспомогательную функцию, которая приводит символ `char` к нижнему регистру: `char make_lower(char c)`. Внутри неё вызовите `std::tolower()` от символа, приведённого к `unsigned char`. Результатом вызова `std::tolower()` будет `unsigned char`. Поэтому его нужно привести обратно к `char`. {.task_hint}
```cpp {.task_answer}
char make_lower(char c)
{
return static_cast<char>(std::tolower(static_cast<unsigned char>(c)));
}
void lower(std::vector<std::string> & words)
{
for (auto & w: words)
std::transform(w.cbegin(), w.cend(), w.begin(), make_lower);
}
```
Цикл `range-for` также позволяет итерироваться по контейнерам, хранящим пары ключ-значение. Это особенно удобно в связке с конструкцией [structured binding](/courses/cpp/chapters/cpp_chapter_0073/#block-structured-binding):
```cpp {.example_for_playground .example_for_playground_010}
std::map<std::string, std::string> headers = {
{"Accept", "text/html"},
{"Accept-Charset", "utf-8"},
{"Cache-Control", "no-cache"}
};
for (auto [k, v]: headers)
std::println("Header: {}. Value: {}", k, v);
```
```
Header: Accept. Value: text/html
Header: Accept-Charset. Value: utf-8
Header: Cache-Control. Value: no-cache
```
Здесь на каждой итерации цикла в переменную `k` сохраняется копия ключа, а в `v` — копия его значения. Заменим копирование на работу со ссылками на ключи и значения:
```cpp {.example_for_playground .example_for_playground_011}
for (auto & [k, v]: headers)
std::println("Header: {}. Value: {}", k, v);
```
Уже лучше! Но это код можно ещё чуть-чуть усовершенствовать. Ведь в данном случае нам не требуется возможность изменять значение по ссылке: достаточно только доступа на чтение. А значит, вместо обычной ссылки правильнее использовать константную.
## Ссылки и константность
Зачастую требуется сделать так, чтобы через ссылку можно было только читать, но не изменять значение. Именно эту задачу решают константные ссылки. Их также называют ссылками на константные объекты. {#block-const}
Чтобы сделать ссылку константной, к её типу добавляется квалификатор `const`. Как и при объявлении любой переменной, тип и `const` могут идти в любом порядке:
```cpp
const T &
```
```cpp
T const &
```
В этом примере мы создаём константную ссылку, но пытаемся обратиться к ней на запись. Это приводит к ошибке компиляции:
```cpp {.example_for_playground .example_for_playground_012}
int val = 16;
const int & ref = val;
++val; // ок
std::println("{}", ref); // ок: обращение по ссылке на чтение
++ref; // ошибка: обращение на запись
```
```
main.cpp:12:5: error: cannot assign to variable 'ref' with const-qualified type 'const int &'
12 | ++ref;
| ^ ~~~
```
Константные ссылки активно используются в функциях, которые должны получить доступ к объекту только на чтение.
```cpp
bool is_localhost(const IpAddr & ip)
{
// Только читаем поля объекта ip
}
```
Реализуйте функцию `most_common_word()`, которая принимает два параметра: строку `text` и неупорядоченное множество из строк `stop_words`. Оба параметра передаются по константной ссылке. {.task_text}
Функция должна вернуть слово, встречающееся в `text` чаще всего и не входящее в `stop_words`. Строка `text` состоит из слов, разделённых одним пробелом. Считаем, что строка не может начинаться и заканчиваться пробелом. Если она пустая, то функция должна вернуть пустую строку. {.task_text}
Например, для `text="a bb a bb"` и `stop_words={"a", "c"}` функция должна вернуть строку `"bb"`. {.task_text}
```cpp {.task_source #cpp_chapter_0141_task_0070}
// Ваша реализация most_common_word()
```
Для разбиения текста по пробелам вам помогут методы строки [find()](https://en.cppreference.com/w/cpp/string/basic_string/find.html) и [substr()](https://en.cppreference.com/w/cpp/string/basic_string/substr.html). Для построения частотного словаря слов пригодится `std::unordered_map` с ключами - строками и значениями - количеством их вхождений в `text`. Чтобы найти в этом словаре слово с максимальной частотой, поможет алгоритм [std::max_element()](https://en.cppreference.com/w/cpp/algorithm/max_element.html). {.task_hint}
```cpp {.task_answer}
using KV = std::pair<std::string, std::size_t>;
bool less(const KV & a, const KV & b)
{
return a.second < b.second;
}
std::string most_common_word(const std::string & text,
const std::unordered_set<std::string> & stop_words)
{
if (text.empty())
return {};
std::unordered_map<std::string, std::size_t> freq;
const char delim = ' ';
std::size_t pos = text.find(delim);
std::size_t pos_prev = 0;
while(pos != std::string::npos)
{
std::string word = text.substr(pos_prev, pos - pos_prev);
if (!stop_words.contains(word))
freq[word] += 1;
pos_prev = pos + 1;
pos = text.find(delim, pos_prev);
}
std::string word = text.substr(pos_prev,
std::min(pos, text.size()) - pos_prev + 1);
if (!stop_words.contains(word))
freq[word] +=1;
auto it = std::max_element(freq.begin(), freq.end(), less);
return it->first;
}
```
----------
## Резюме
- Про ссылку (reference) удобно думать как про псевдоним существующей переменной.
- При создании ссылку нужно инициализировать.
- Ссылку нельзя переназначить.
- Константная ссылка — это ссылка, по которой можно только читать значение, но не изменять его.
- Если функция принимает параметр _по значению,_ то при её вызове происходит копирование соответствующего аргумента.
- Если функция принимает параметр _по ссылке,_ то она работает с исходным объектом. Копирования не происходит.
Наша группа в telegram. Здесь можно задавать вопросы и общаться.
Задонатить. Если вам нравится курс, вы можете поддержать развитие площадки!