# Глава 8.1. Немодифицирующие алгоритмы
Алгоритмы стандартной библиотеки C++ — это шаблонные функции для поиска, сортировки, слияния и других распространённых действий над диапазонами и отдельными значениями.
## Мотивация применять алгоритмы
Умение своевременно использовать алгоритмы отличает опытного C++ разработчика от новичка. Взгляните на наивную реализацию поиска максимального элемента вектора:
```cpp {.example_for_playground .example_for_playground_001}
std::vector<double> temperatures = read_temperatures();
if (temperatures.empty())
{
std::println("Waiting for new data...");
}
else
{
double max = temperatures.front();
for (double t: temperatures)
{
if (max < t)
max = t;
}
std::println("Max temperature: {}", max);
}
```
Перепишем этот пример с использованием алгоритма [std::max_element()](https://en.cppreference.com/w/cpp/algorithm/max_element):
```cpp {.example_for_playground .example_for_playground_002}
std::vector<double> temperatures = read_temperatures();
const auto it_max = std::max_element(temperatures.begin(), temperatures.end());
if (it_max == temperatures.end())
std::println("Waiting for new data...");
else
std::println("Max temperature: {}", *it_max);
```
Этот код делает то же самое, но выглядит короче и понятнее. Похожий пример мы [приводили,](/courses/cpp/chapters/cpp_chapter_0011/#block-zero-overhead) когда описывали одно из достоинств C++ — абстракции с нулевой стоимостью.
Всегда предпочитайте стандартные алгоритмы и их комбинацию наивным самописным решениям. Вы получите преимущества:
- Более выразительный и понятый код. Алгоритмы стандартной библиотеки можно сравнить со словарным запасом, которым должен владеть разработчик на C++.
- Повышение уровня абстракции без потери производительности.
- Предотвращение типичных проблем: избыточной алгоритмической сложности, ошибок в граничных условиях.
Если вам нужно выполнить над контейнером какое-то типовое действие, то скорее всего оно реализовано в стандартной библиотеке. Просто пройдитесь по [списку алгоритмов](https://en.cppreference.com/w/cpp/algorithm) и выберите подходящий.
## Обзор алгоритмов стандартной библиотеки
Стандарт языка описывает [сотни алгоритмов.](https://en.cppreference.com/w/cpp/algorithm) В прошлых главах вы уже познакомились с [std::for_each()](/courses/cpp/chapters/cpp_chapter_0011/#block-for-each), [std::clamp()](/courses/cpp/chapters/cpp_chapter_0011/#block-clamp), [std::min(), std::max()](/courses/cpp/chapters/cpp_chapter_0031/#block-min-max), [std::reverse()](/courses/cpp/chapters/cpp_chapter_0061/#block-vector), [std::find(), std::find_if()](/courses/cpp/chapters/cpp_chapter_0061/#block-find-if) и [std::sort()](/courses/cpp/chapters/cpp_chapter_0073/#block-sort).
Перечислим самые популярные классы задач, решаемые с помощью алгоритмов. Для каждого из них приведём в пример по паре функций.
- Изменение элементов диапазона.
- [std::for_each()](https://en.cppreference.com/w/cpp/algorithm/for_each), [std::replace](https://en.cppreference.com/w/cpp/algorithm/replace).
- Поиск и подсчёт.
- [std::find()](https://en.cppreference.com/w/cpp/algorithm/find), [std::count()](https://en.cppreference.com/w/cpp/algorithm/count).
- Бинарный поиск в отсортированном диапазоне.
- [std::lower_bound()](https://en.cppreference.com/w/cpp/algorithm/lower_bound), [std::equal_range()](https://en.cppreference.com/w/cpp/algorithm/equal_range).
- Копирование.
- [std::copy()](https://en.cppreference.com/w/cpp/algorithm/copy), [std::copy_backward](https://en.cppreference.com/w/cpp/algorithm/copy_backward).
- Присваивание элементам значений по некоторым правилам.
- [std::fill()](https://en.cppreference.com/w/cpp/algorithm/fill), [std::generate()](https://en.cppreference.com/w/cpp/algorithm/generate).
- Удаление элементов.
- [std::remove()](https://en.cppreference.com/w/cpp/algorithm/remove), [std::unique()](https://en.cppreference.com/w/cpp/algorithm/unique). Оба алгоритма используются в связке с методом контейнера `erase()` или функцией [std::erase()](https://en.cppreference.com/w/cpp/container/vector/erase2).
- Изменение порядка элементов.
- [std::reverse()](https://en.cppreference.com/w/cpp/algorithm/reverse), [std::shuffle()](https://en.cppreference.com/w/cpp/algorithm/random_shuffle).
- Сортировка.
- [std::sort()](https://en.cppreference.com/w/cpp/algorithm/sort), [std::nth_element()](https://en.cppreference.com/w/cpp/algorithm/nth_element).
- Операции над множествами.
- [std::includes()](https://en.cppreference.com/w/cpp/algorithm/includes), [std::set_intersection()](https://en.cppreference.com/w/cpp/algorithm/set_intersection).
- Слияние отсортированных диапазонов.
- [std::merge()](https://en.cppreference.com/w/cpp/algorithm/merge), [std::inplace_merge()](https://en.cppreference.com/w/cpp/algorithm/inplace_merge).
- Операции над структурой данных [куча](https://ru.wikipedia.org/wiki/%D0%9A%D1%83%D1%87%D0%B0_(%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%B4%D0%B0%D0%BD%D0%BD%D1%8B%D1%85)) (heap).
- [std::push_heap()](https://en.cppreference.com/w/cpp/algorithm/push_heap), [std::make_heap()](https://en.cppreference.com/w/cpp/algorithm/make_heap).
- Расчет максимума и минимума.
- [std::minmax()](https://en.cppreference.com/w/cpp/algorithm/minmax), [std::clamp()](https://en.cppreference.com/w/cpp/algorithm/clamp).
- Получение из диапазона некоего значения. Например, суммы элементов.
- [std::accumulate()](https://en.cppreference.com/w/cpp/algorithm/accumulate), [std::reduce()](https://en.cppreference.com/w/cpp/algorithm/reduce).
- Все остальное.
У алгоритмов есть перегрузки с разным набором параметров. Например, одним из параметров может выступать [политика выполнения](https://en.cppreference.com/w/cpp/algorithm/execution_policy_tag_t) (execution policy). Она появилась в C++17 и позволяет распараллеливать работу алгоритма. Это открывает возможности многопоточности и векторизации без единой дополнительной строки кода. С ней вы поработаете в следующих главах.
Многие алгоритмы принимают итераторы на диапазон внутри контейнера. Он включает итератор на начало и _не_ включает итератор на конец:
```cpp {.example_for_playground .example_for_playground_003}
std::vector<int> vals = {1, 2, 3, 4, 5, 6};
// Переворачиваем последовательность элементов
// с индексами 1, 2.
std::reverse(vals.begin() + 1, vals.begin() + 3);
std::println("{}", vals);
```
```
[1, 3, 2, 4, 5, 6]
```
Мы рассмотрим только алгоритмы, которые пригодятся в первую очередь.
## Поиск
Алгоритм `std::find()` нужен для поиска элемента в коллекции. Как и некоторые другие алгоритмы, он обладает вариациями с суффиксами `_if` и `_if_not` в имени. Рассмотрим, чем они отличаются.
Функция [std::find()](https://en.cppreference.com/w/cpp/algorithm/find) принимает итераторы на диапазон и искомое значение. И возвращает итератор на первый элемент диапазона, равный значению.
В этом примере мы получаем итератор на элемент, а затем меняем его значение:
```cpp {.example_for_playground .example_for_playground_004}
std::array<int, 5> raw_data = {9, -1, 2, 2, 3};
auto it = std::find(raw_data.begin(), raw_data.end(), -1);
if (it != raw_data.end())
*it = 0;
std::println("{}", raw_data);
```
```
[9, 0, 2, 2, 3]
```
Чему равна переменная `i`? {.task_text}
С функцией `std::distance()` вы [познакомились](/courses/cpp/chapters/cpp_chapter_0061/#block-distance) в главе про итераторы. {.task_text}
```cpp {.example_for_playground}
import std;
int main()
{
std::vector<int> ids = {568, 91, 55, 91, 104};
auto rit = std::find(ids.rbegin(), ids.rend(), 91);
std::size_t i = rit == ids.rend() ?
0 : std::distance(ids.begin(), (rit + 1).base());
}
```
```consoleoutput {.task_source #cpp_chapter_0081_task_0010}
```
В алгоритм `std::find()` передаются обратные итераторы, значит поиск начинается с конца. Функция `std::find()` возвращает обратный итератор `rit`, и выражение `(rit + 1).base()` позволяет получить из обратного итератора обычный. Затем расчитывается расстояние между первым элементом вектора и элементом, на который указывает итератор. {.task_hint}
```cpp {.task_answer}
3
```
Функция [std::find_if()](https://en.cppreference.com/w/cpp/algorithm/find) вместо значения принимает [предикат](/courses/cpp/chapters/cpp_chapter_0056/#block-predicate) и применяет его к элементам диапазона. Она возвращает итератор на первый элемент, для которого предикат вернул `true`.
У функции [std::find_if_not()](https://en.cppreference.com/w/cpp/algorithm/find) единственное отличие от `std::find_if()`: она возвращает итератор на элемент, для которого предикат вернул `false`.
Чтобы искать элементы начиная с конца диапазона, в алгоритм поиска передаются [обратные итераторы:](/courses/cpp/chapters/cpp_chapter_0062/#block-reverse-iterators)
```cpp {.example_for_playground .example_for_playground_005}
std::deque<int> d = {5, 6, 10, 10, 1};
auto rit = std::find(d.rbegin(), d.rend(), 10);
std::println("{}", std::distance(d.begin(), (rit + 1).base()));
```
```
3
```
Функция `std::find()` и её вариации нужны для поиска одного элемента. Они работают за линейное время `O(N)`, где `N` — длина диапазона.
Для поиска одного диапазона внутри другого используется алгоритм [std::search()](https://en.cppreference.com/w/cpp/algorithm/search). Он работает за время `O(N * M)`, где `N` и `M` — длины диапазонов.
Для определения, соответствуют ли элементы диапазона предикату, есть алгоритмы [std::all_of(), std::any_of() и std::none_of()](https://en.cppreference.com/w/cpp/algorithm/all_any_none_of). Их алгоритмическая сложность — `O(N)`.
Реализуйте функцию `accepts_gzip()`. Она принимает вектор из HTTP-заголовков. Каждый заголовок — это пара, в которой поле `first` хранит имя заголовка, а `second` — его значение. Функция должна вернуть `true`, если среди заголовков содержится `"Accept-Encoding"`, значение которого содержит подстроку `"gzip"`. {.task_text}
Попробуйте решить задачу двумя способами: сначала через `std::find_if()`, а затем через `std::any_of()`. {.task_text}
```cpp {.task_source #cpp_chapter_0081_task_0020}
bool accepts_gzip(std::vector<std::pair<std::string, std::string>> headers)
{
}
```
Вам потребуется завести вспомогательную функцию-предикат, которая сравнивает поле `first` объекта `std::pair` с нужным заголовком. И в случае успеха ищет в поле `second` подстроку `"gzip"`. Вам пригодится метод строки `find()`, с которым вы [уже работали.](/courses/cpp/chapters/cpp_chapter_0031/#block-string-find) {.task_hint}
```cpp {.task_answer}
bool accepts(std::pair<std::string, std::string> header)
{
if (header.first != "Accept-Encoding")
return false;
return (header.second.find("gzip") != std::string::npos);
}
bool accepts_gzip(std::vector<std::pair<std::string, std::string>> headers)
{
return std::find_if(headers.begin(), headers.end(), accepts)
!= headers.end();
// Еще более удачный вариант:
// return std::any_of(headers.begin(), headers.end(), accepts);
}
```
## Бинарный поиск
Если элементы диапазона отсортированы, то поиск по ним можно выполнить быстрее, чем за `O(N)`. Для этого вместо полного перебора применяется [бинарный поиск.](https://ru.wikipedia.org/wiki/%D0%94%D0%B2%D0%BE%D0%B8%D1%87%D0%BD%D1%8B%D0%B9_%D0%BF%D0%BE%D0%B8%D1%81%D0%BA)
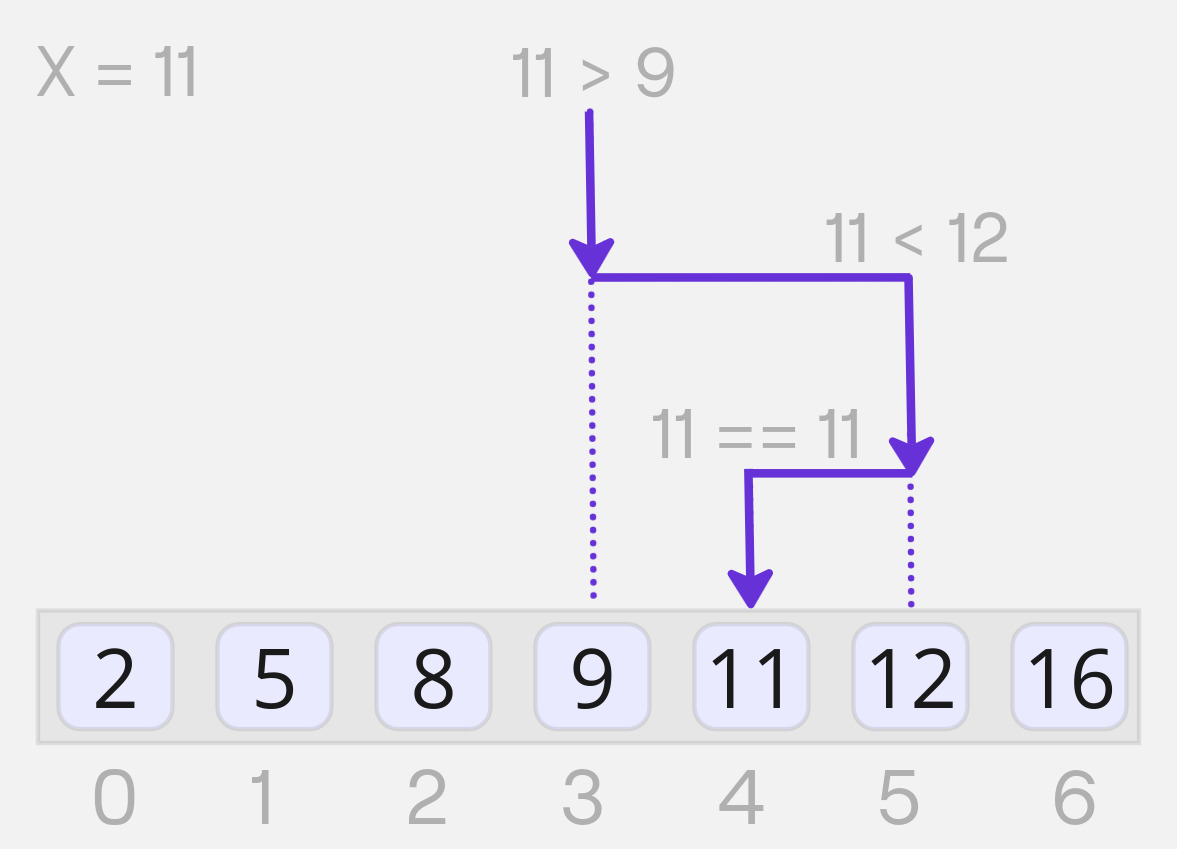
Бинарный поиск выглядит предельно просто. Допустим, мы ищем в отсортированном диапазоне элемент, равный `X`.
1. Сравниваем с `X` элемент в середине диапазона.
2. Если его значение меньше `X`, то продолжаем поиск в первой половине диапазона. Иначе — во второй.
3. Сравниваем с `X` элемент в середине выбранной половины.
4. Выполняем шаги 2 и 3, пока не найдём `X`, либо пока не получим пустой диапазон. Это будет означать, что поиск завершился неудачей.
На каждой итерации бинарного поиска рассматриваемый диапазон сокращается в 2 раза. Значит, алгоритм работает за `O(log(N))`.
Так выглядит бинарный поиск на примере небольшого диапазона:
 {.illustration}
Понять алгоритм бинарного поиска просто, но совершить ошибку в его реализации — ещё проще. Чаще всего ошибаются при определении середины и границ диапазона. Это приводит к вечным циклам, пропуску элементов и выходу за границы диапазона. Поэтому реализация бинарного поиска — одна из классических задач на собеседованиях.
Напишите шаблонную функцию `bin_search()`, которая принимает итераторы на отсортированный диапазон: `first` — итератор на первый элемент, `last` — итератор, указывающий за последний элемент. Также функция принимает искомое значение `x`. Для простоты будем считать, что `x` встречается в диапазоне не более 1 раза. {.task_text}
Функция должна вернуть итератор на элемент, равный `x`, либо итератор `last`, если элемент не обнаружен. {.task_text}
Например, для диапазона `[2, 5, 8, 9, 11, 12, 16]` и значения `x=11` функция должна вернуть итератор на элемент с индексом 4. {.task_text}
Не у всех контейнеров итераторы поддерживают инкремент через `+` и `+=`. Для перемещения итератора на `n` позиций вперёд используйте функцию [std::advance()](https://cppreference.com/w/cpp/iterator/advance): `std::advance(it, n)`. Если `n` — отрицательное число, то итератор передвинется на `n` позиций назад. {.task_text}
```cpp {.task_source #cpp_chapter_0081_task_0030}
template<class It, class Val>
It bin_search(It first, It last, Val x)
{
}
```
Определите длину диапазона через `std::distance()`. Середина диапазона находится на половине длины от его начала. Сдвигайте середину диапазона функцией `std::advance()`. {.task_hint}
```cpp {.task_answer}
template<class It, class Val>
It bin_search(It first, It last, Val x)
{
auto len = std::distance(first, last);
while (len > 0)
{
const auto half = len / 2;
auto middle = first;
std::advance(middle, half);
if (*middle < x)
{
first = middle;
++first;
len -= half + 1;
}
else
{
len = half;
}
}
return (first != last && *first != x) ? last : first;
}
```
В стандартной библиотеке есть алгоритм [std::binary_search()](https://en.cppreference.com/w/cpp/algorithm/binary_search). Но он лишь _проверяет,_ что диапазон содержит интересующий элемент:
```cpp {.example_for_playground .example_for_playground_006}
std::string s = "abcdefg";
std::println("{}", std::binary_search(s.begin() + 2, s.end() - 1, 'e'));
```
```
true
```
Зато алгоритмы [std::lower_bound()](https://en.cppreference.com/w/cpp/algorithm/lower_bound) и [std::upper_bound()](https://en.cppreference.com/w/cpp/algorithm/upper_bound) возвращают итератор.
Они принимают итераторы на упорядоченный диапазон и искомое значение `x`:
- `std::lower_bound()` возвращает итератор на первое значение, _не меньшее_ `x`.
- `std::upper_bound()` возвращает итератор на первое значение, _большее_ `x`.
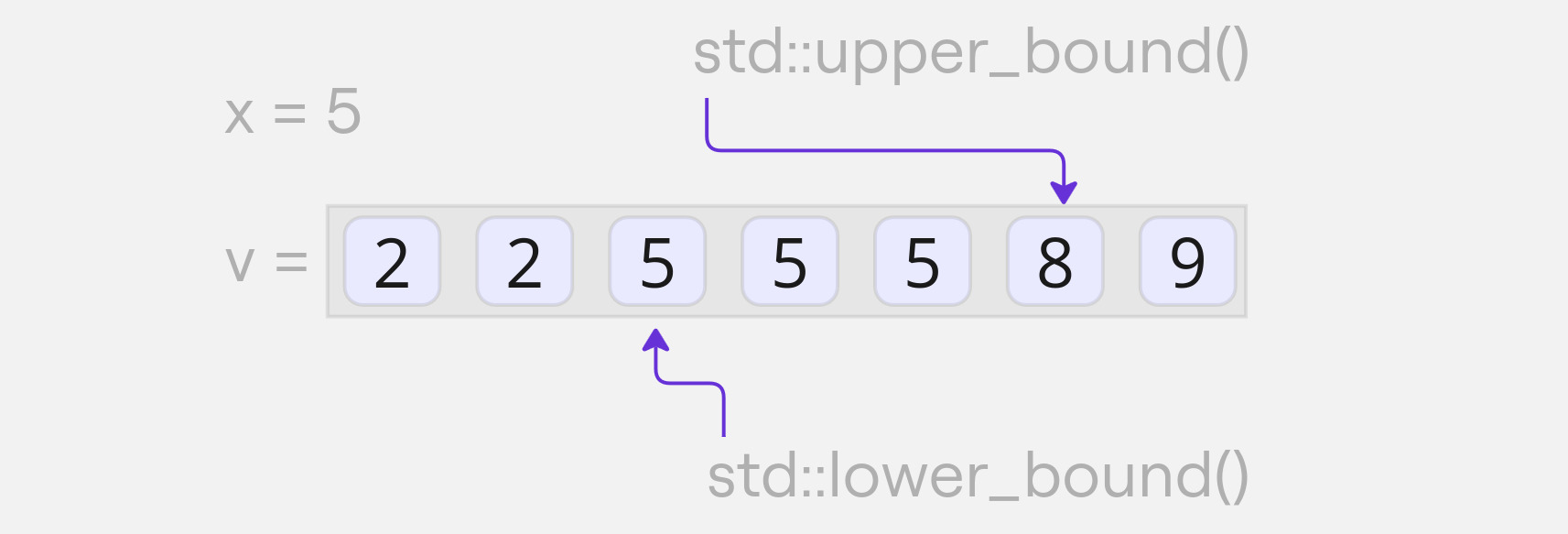
С помощью этих алгоритмов определим диапазон отсортированного вектора `v`, в котором находятся элементы, равные 5:
```cpp {.example_for_playground .example_for_playground_007}
int x = 5;
std::vector<int> v = {2, 2, 5, 5, 5, 8, 9};
auto it_l = std::lower_bound(v.begin(), v.end(), x);
std::println("lower bound. index = {}. value = {}",
std::distance(v.begin(), it_l), *it_l);
auto it_u = std::upper_bound(v.begin(), v.end(), x);
std::println("upper bound. index = {}. value = {}",
std::distance(v.begin(), it_u), *it_u);
```
```
lower bound. index = 2. value = 5
upper bound. index = 5. value = 8
```
 {.illustration}
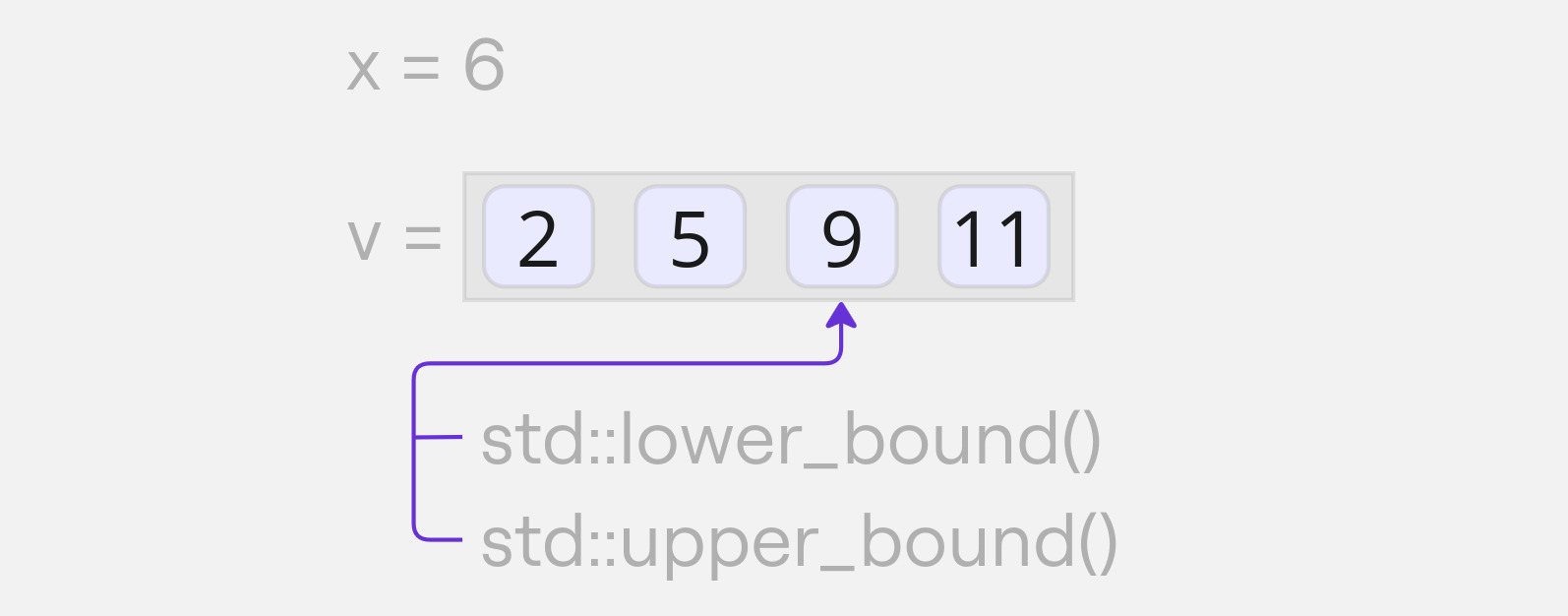
Если элемент отсутствует в диапазоне, `std::lower_bound()` и `std::upper_bound()` возвращают одинаковый результат:
```cpp {.example_for_playground .example_for_playground_008}
int x = 6;
std::vector<int> v = {2, 5, 9, 11};
auto it_l = std::lower_bound(v.begin(), v.end(), x);
std::println("lower bound. index = {}. value = {}",
std::distance(v.begin(), it_l), *it_l);
auto it_u = std::upper_bound(v.begin(), v.end(), x);
std::println("upper bound. index = {}. value = {}",
std::distance(v.begin(), it_u), *it_u);
```
```
lower bound. index = 2. value = 9
upper bound. index = 2. value = 9
```
 {.illustration}
Как видите, итераторы от `std::lower_bound()` и `std::upper_bound()` _ограничивают_ диапазон элементов, равных указанному значению. Чтобы получить этот диапазон, можно воспользоваться всего одной функцией. Она называется [std::equal_range()](https://en.cppreference.com/w/cpp/algorithm/equal_range) и возвращает пару итераторов.
Напишите функцию `count_vals()`, принимающую отсортированный вектор и значение. Функция должна вернуть, сколько раз значение встречается в векторе. {.task_text}
Например, для вектора `[6, 6, 8, 8, 9]` и значения 8 функция должна вернуть 2. {.task_text}
```cpp {.task_source #cpp_chapter_0081_task_0040}
std::size_t count_vals(std::vector<int> data, int val)
{
}
```
Для получения диапазона элементов, равных `val`, воспользуйтесь [std::equal_range()](https://en.cppreference.com/w/cpp/algorithm/equal_range). Функция возвращает пару итераторов. Верните расстояние между ними, вызвав [std::distance()](https://en.cppreference.com/w/cpp/iterator/distance). {.task_hint}
```cpp {.task_answer}
std::size_t count_vals(std::vector<int> data, int val)
{
const auto it_pair = std::equal_range(data.begin(), data.end(), val);
return std::distance(it_pair.first, it_pair.second);
}
```
## Подсчет
Для подсчёта количества элементов диапазона, удовлетворяющих некоторому критерию, есть алгоритмы [std::count() и std::count_if()](https://en.cppreference.com/w/cpp/algorithm/count):
- `std::count()` принимает итераторы на диапазон и значение. И возвращает количество элементов диапазона, равных значению.
- `std::count_if()` вместо значения принимает предикат.
```cpp {.example_for_playground}
import std;
int main()
{
std::forward_list<std::string> blocks = {"a", "b", "b", "c"};
// В немодифицирующие алгоритмы можно передавать
// обычные итераторы, а можно — константные
const std::size_t n = std::count(blocks.cbegin(), blocks.cend(), "b");
std::println("{}", n);
}
```
```
2
```
Чему равно значение переменной `n`? {.task_text}
```cpp {.example_for_playground}
import std;
bool is_neg(int val)
{
return val < 0;
}
int main()
{
std::vector<int> measurements = {-10, 5, 10, -2, -2};
std::size_t n = std::count_if(measurements.begin() + 1,
measurements.end() - 1,
is_neg);
}
```
```consoleoutput {.task_source #cpp_chapter_0081_task_0080}
```
Подсчет отрицательных элементов осуществляется начиная с индекса 1 и до индекса 3 включительно. То есть среди элементов `5, 10, -2`. {.task_hint}
```cpp {.task_answer}
1
```
Еще одна распространённая задача — найти сумму или произведение элементов диапазона. Ее можно решить с помощью алгоритмов [std::accumulate()](https://en.cppreference.com/w/cpp/algorithm/accumulate) и [std::reduce()](https://en.cppreference.com/w/cpp/algorithm/reduce). {#block-accumulate}
Функция `std::accumulate()` принимает итераторы на диапазон и начальное значение. И возвращает сумму начального значения с элементами диапазона:
```cpp {.example_for_playground .example_for_playground_016}
std::vector<double> distances = {34.3, 18.0, 51.5};
// Тип возвращаемого значения совпадает с типом третьего аргумента:
double total_distance = std::accumulate(distances.cbegin(),
distances.cend(),
0.0);
std::println("{}", total_distance);
```
```
103.8
```
Функция `get_average()` принимает вектор чисел и возвращает их среднее арифметическое. В ней допущена ошибка. Исправьте её и перепишите код с использованием `std::accumulate()`. {.task_text}
```cpp {.task_source #cpp_chapter_0081_task_0090}
double get_average(std::vector<int> values)
{
double sum = 0.0;
for (double val: values)
sum += val;
return sum / values.size();
}
```
В исходной реализации функции если вектор `values` пуст, происходит деление на ноль. {.task_hint}
```cpp {.task_answer}
double get_average(std::vector<int> values)
{
if (values.empty())
return 0.0;
return std::accumulate(values.begin(),
values.end(),
0.0) / values.size();
}
```
У `std::accumulate()` есть перегрузка, дополнительно принимающая функцию с двумя параметрами. Она нужна для расчёта произведения или любого другого значения. {#block-accumulate-overload}
Что будет выведено в консоль? {.task_text}
Функция [std::to_string()](https://en.cppreference.com/w/cpp/string/basic_string/to_string) переводит число в строку. {.task_text}
```cpp
import std;
std::string dot_fold(std::string left, int right)
{
return left + "." + std::to_string(right);
}
int main()
{
std::vector<int> v = {5, 2, 0};
std::println("{}", std::accumulate(v.cbegin() + 1,
v.cend(),
std::to_string(v.front()),
dot_fold));
}
```
```consoleoutput {.task_source #cpp_chapter_0081_task_0100}
```
В данном случае `std::accumulate()` накапливает результат, начиная с нулевого элемента вектора, сконвертированного в строку. К этой строке через точку прибавляются последующие элементы вектора. {.task_hint}
```cpp {.task_answer}
5.2.0
```
## Домашнее задание
Самостоятельно разберитесь, в чем разница между алгоритмами [std::accumulate()](https://en.cppreference.com/w/cpp/algorithm/accumulate) и [std::reduce()](https://en.cppreference.com/w/cpp/algorithm/reduce).
----------
## Резюме
- Всегда предпочитайте алгоритмы стандартной библиотеки наивным самописным реализациям.
- Алгоритмы стандартной библиотеки — это шаблонные функции для поиска, сортировки, копирования диапазонов и других полезных операций.
- Старайтесь периодически просматривать, [какие алгоритмы есть](https://en.cppreference.com/w/cpp/algorithm) в стандартной библиотеке. Применяйте их в своём коде.
Наша группа в telegram. Здесь можно задавать вопросы и общаться.
Задонатить. Если вам нравится курс, вы можете поддержать развитие площадки!