Главная /
Курсы /
C++ по спирали /
Глава 7. Обзор контейнеров /
Неупорядоченные ассоциативные контейнеры
# Глава 7.4. Неупорядоченные ассоциативные контейнеры
Имена классов неупорядоченных ассоциативных контейнеров похожи на имена упорядоченных. Их отличает лишь префикс `unordered`. Набор методов тоже практически совпадает. Поэтому в этой главе мы не будем заново описывать, как работают методы `find()`, `try_emplace()` и другие. А сразу перейдём к практике.
 {.illustration}
Но внутренней реализацией эти категории контейнеров принципиально отличаются:
- Элементы упорядоченных ассоциативных контейнеров всегда отсортированы, а элементы неупорядоченных хранятся в произвольном порядке.
- Упорядоченные ассоциативные контейнеры — это деревья поиска, а неупорядоченные — [хеш-таблицы.](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0)
Поиск, добавление и удаление элементов в хеш-таблице осуществляется по ключу. Для этого к ключу `key` применяется хеш-функция. Она преобразует ключ в целое число. Затем по этому числу высчитывается индекс `i` в массиве. Например, делением по модулю, равному длине `n` массива:
```
i = hash(key) % n
```
По этому индексу в массиве хранится привязанное к ключу значение.
Множество ключей потенциально бесконечно. А количество значений целого числа ограничено. Значит, неизбежны ситуации, когда для разных ключей хеш-функция вернёт одно и то же значение. Это называется коллизией. Частота коллизий зависит от того, насколько удачно подобрана хеш-функция.
Для разрешения коллизий известно [несколько способов.](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88-%D1%82%D0%B0%D0%B1%D0%BB%D0%B8%D1%86%D0%B0#%D0%A0%D0%B0%D0%B7%D1%80%D0%B5%D1%88%D0%B5%D0%BD%D0%B8%D0%B5_%D0%BA%D0%BE%D0%BB%D0%BB%D0%B8%D0%B7%D0%B8%D0%B9) В реализациях стандартной библиотеки используется метод цепочек (chaining). Иногда его называют методом списков, потому что каждый элемент массива указывает на односвязный список. Он содержит пары ключ-значение. Если коллизий по данному хеш-значению не было, список состоит из единственного элемента:
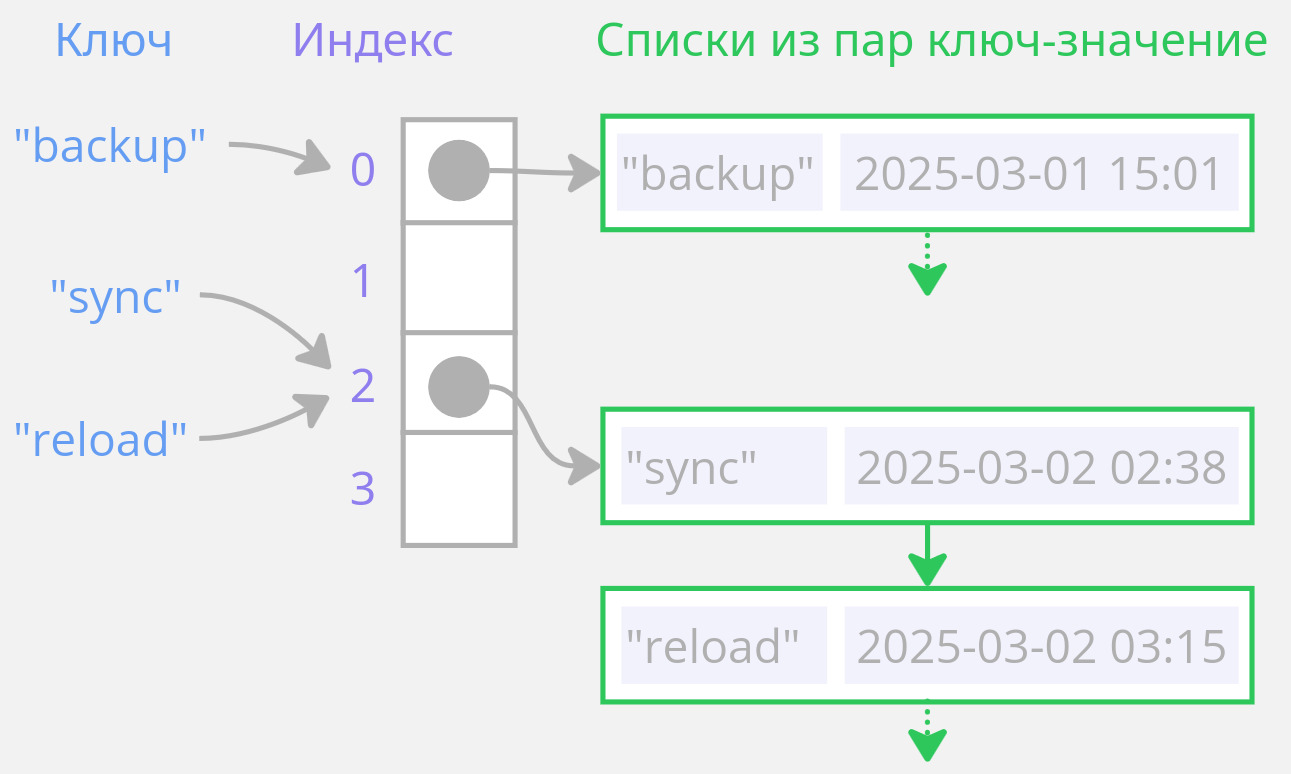 {.illustration}
Чтобы тип данных мог быть ключом в неупорядоченном ассоциативном контейнере, должны выполняться условия:
- К нему применимо сравнение оператором `==`.
- Для него определена хеш-функция. По умолчанию используется шаблонная функция `std::hash<Key>()`.
Интерфейсы упорядоченных и неупорядоченных ассоциативных контейнеров практически идентичны, поэтому подробно останавливаться на них не имеет смысла.
## Класс unordered_set
Множество ключей [std::unordered_set](https://en.cppreference.com/w/cpp/container/unordered_set) используется для быстрой проверки на уникальность и для подсчёта количества уникальных объектов.
```cpp {.example_for_playground .example_for_playground_022}
std::unordered_set<std::string> bluetooth_protocols = {"BNEP"};
bluetooth_protocols.insert("RFCOMM");
bluetooth_protocols.insert("SDP");
bluetooth_protocols.insert("SDP");
bluetooth_protocols.erase("BNEP");
auto it = bluetooth_protocols.find("RFCOMM");
std::println("Key RFCOMM exists: {}", it != bluetooth_protocols.end());
std::println("Set: {} Size: {}", bluetooth_protocols, bluetooth_protocols.size());
```
```
Key RFCOMM exists: true
Set: {"SDP", "RFCOMM"} Size: 2
```
Метод [insert()](https://en.cppreference.com/w/cpp/container/unordered_set/insert.html) контейнера `std::unordered_set`, как и этот же метод других контейнеров, позволяет вставлять целые диапазоны:
```cpp
bluetooth_protocols.insert(src.begin(), src.end())
```
## Класс unordered_map
Класс [std::unordered_map](https://en.cppreference.com/w/cpp/container/unordered_map) позволяет хранить пары ключ-значение с уникальным ключом.
Дан массив целых чисел `v` и целое число `n`. Нужно посчитать, сколько уникальных пар элементов массива в сумме дают `n`. {.task_text}
Примеры: {.task_text}
Если `v = {3, 2, 1, 2}` и `n = 3`, то количество пар равно 2. Это пары элементов с индексами (1, 2), (2, 3). {.task_text}
Если `v = {1, 2, 3, 2, 2, 4, 0}` и `n = 4`, то количество пар равно 5. Это пары элементов с индексами (0, 2), (1, 3), (1, 4), (3, 4), (5, 6). {.task_text}
Эта задача имеет короткое решение, работающее за `O(N)`. Если оно не приходит вам в голову, воспользуйтесь подсказкой. {.task_text}
```cpp {.task_source #cpp_chapter_0074_task_0040}
int count_pairs(std::vector<int> v, int n)
{
}
```
Заведите частотный словарь `freq` с ключами — элементами `v` и значениями — их частотой. Вначале словарь пустой. Перебирайте все элементы `v`. Для каждого элемента `x` рассчитайте его потенциальную пару: `y = n - x`. Если `y` уже содержится в словаре, прибавьте его частоту к `res`. После чего сделайте инкремент частоты `x` в `freq`. {.task_hint}
```cpp {.task_answer}
int count_pairs(std::vector<int> v, int n)
{
std::unordered_map<int, int> freq;
int res = 0;
for (int x: v)
{
const int y = n - x;
const auto it = freq.find(y);
if (it != freq.end())
res += it->second;
++freq[x];
}
return res;
}
```
Реализуйте функцию `consists_of()`, которая принимает текст послания `message` и текст журнала `magazine`. Функция возвращает `true`, если текст послания может быть составлен из вырезанных из журнала букв. Оба параметра могут содержать только латинские буквы в нижнем регистре и пробелы. При подсчёте пробелы учитывать не нужно. {.task_text}
Например, `consists_of("bab", "abbc")` вернёт `true`, а `consists_of("bab", "abc")` — `false`. {.task_text}
В своём решении используйте `std::unordered_map`. {.task_text}
```cpp {.task_source #cpp_chapter_0074_task_0050}
bool consists_of(std::string message, std::string magazine)
{
}
```
Заведите вспомогательную функцию, которая принимает строку и возвращает `std::unordered_map`, ключи которого — символы, а значения — их частота в строке. Это частотный словарь. Примените эту функцию к тексту журнала. Затем проитерируйтесь по посланию и проверьте, что каждый символ в нем (кроме пробела) содержится в частотном словаре. Если символ найден, уменьшайте по этому ключу частоту на 1. {.task_hint}
```cpp {.task_answer}
std::unordered_map<char, std::size_t> to_dict(std::string text)
{
std::unordered_map<char, std::size_t> dict;
for(char c: text)
{
if (c == ' ')
continue;
auto [it, inserted] = dict.try_emplace(c, 1);
if (!inserted)
++it->second;
}
return dict;
}
bool consists_of(std::string message, std::string magazine)
{
auto dict = to_dict(magazine);
for (char c: message)
{
if (c == ' ')
continue;
auto it = dict.find(c);
if (it == dict.end() || it->second == 0)
return false;
--it->second;
}
return true;
}
```
## Классы unordered_multimap и unordered_multiset
Классы [std::unordered_multimap](https://en.cppreference.com/w/cpp/container/unordered_multimap) и [std::unordered_multiset](https://en.cppreference.com/w/cpp/container/unordered_multiset) не требуют уникальности ключа.
А теперь решим задачу из предыдущего раздела через multi-* версию контейнера. {.task_text}
Реализуйте функцию `consists_of()`, которая принимает текст послания `message` и текст журнала `magazine`. Функция возвращает `true`, если текст послания может быть составлен из вырезанных из журнала букв. Оба параметра могут содержать только латинские буквы в нижнем регистре и пробелы. При подсчёте пробелы учитывать не нужно. {.task_text}
Например, `consists_of("bab", "abbc")` вернёт `true`, а `consists_of("bab", "abc")` — `false`. {.task_text}
В своём решении используйте `std::unordered_multiset`. {.task_text}
```cpp {.task_source #cpp_chapter_0074_task_0060}
bool consists_of(std::string message, std::string magazine)
{
}
```
Заведите контейнер `std::unordered_multiset`, в который добавьте все буквы из текста журнала. Затем проитерируйтесь по тексту послания. Если буква из послания найдена в контейнере, удаляйте её. Если не найдена, это будет означать, что текст послания составить нельзя. {.task_hint}
```cpp {.task_answer}
bool consists_of(std::string message, std::string magazine)
{
std::unordered_multiset<char> mag_chars;
mag_chars.reserve(magazine.size());
mag_chars.insert(magazine.begin(), magazine.end());
for(char c: message)
{
if (c == ' ')
continue;
auto it = mag_chars.find(c);
if (it == mag_chars.end())
return false;
mag_chars.erase(it);
}
return true;
}
```
----------
## Резюме
Алгоритмическая сложность работы с неупорядоченными ассоциативными контейнерами:
 {.illustration}
Наша группа в telegram. Здесь можно задавать вопросы и общаться.
Задонатить. Если вам нравится курс, вы можете поддержать развитие площадки!