# Глава 7.2. Последовательные контейнеры
Последовательные контейнеры представлены массивами, деком и списками.
 {.illustration}
## Класс vector
Класс [std::vector](https://en.cppreference.com/w/cpp/container/vector) — ваш [выбор по умолчанию](https://timsong-cpp.github.io/cppwp/n4950/sequence.reqmts#2) для хранения последовательностей элементов. Это массив с динамически изменяемым размером. В нем есть методы для добавления и удаления элементов на любой позиции.
Тип элемента — это первый параметр шаблона класса `std::vector`. У шаблона есть и другие параметры, но мы не будем их задавать, то есть воспользуемся значениями по умолчанию. {#block-initialization}
```cpp
std::vector<std::string> directions = {"left", "backward", "right"};
```
Для инициализации вектора `directions` мы использовали фигурные скобки, в которых перечислили значения элементов. Это так называемая списочная инициализация ([list-initialization](https://en.cppreference.com/w/cpp/language/list_initialization)). Она появилась в C++11 и позволяет заполнять контейнер в момент создания.
Для доступа к элементам по индексу используется оператор `[]`:
```cpp {.example_for_playground .example_for_playground_001}
std::vector<double> fractions = {0.05, 0.20, 0.80, 0.95};
double a = fractions[3]; // ok
// 3 - максимальный индекс. Что произойдёт на этой строке?
double b = fractions[4];
```
Стандарт C++ относит чтение или запись элемента по несуществующему индексу к неопределённому поведению (UB, undefined behaviour). {#block-ub}
Есть ли в этом коде UB? `Y/N`. {.task_text}
```cpp
std::vector<char> buffer = {'0', '0', '0', '0', '0'};
for (std::size_t i = 0; i <= buffer.size(); ++i)
buffer[i] = '*';
```
```consoleoutput {.task_source #cpp_chapter_0072_task_0010}
```
Обратите внимание на максимальное значение, которое индекс `i` принимает в цикле. {.task_hint}
```cpp {.task_answer}
Y
```
Чтобы не писать проверок, но при этом избежать UB, предусмотрен метод `at()`. Если индекс выходит за границы массива, метод бросает исключение `std::out_of_range`:
```cpp {.example_for_playground .example_for_playground_002}
const std::vector<std::string> headers = {"Accept", "Cookie", "Expires"};
try
{
const std::string header = headers.at(10);
// ...
}
catch(const std::out_of_range & e)
{
std::println("Exception in {}", e.what());
}
```
В классе `std::vector` реализовано множество других полезных методов. В первую очередь вам потребуются:
- `size()` — получение длины массива.
- `empty()` — проверка, является ли массив пустым. Хорошим правилом считается использовать проверку `if (v.empty())` вместо `if (v.size() == 0)`.
- `front()` — возвращает первый элемент.
- `back()` — возвращает последний элемент.
- `push_back()` — добавляет элемент в конец. Например, `v.push_back(1)`.
- `insert()` — добавляет элемент перед итератором. Вызов `v.insert(v.begin(), 1)` добавит элемент 1 в начало контейнера. У метода есть [несколько перегрузок.](https://en.cppreference.com/w/cpp/container/vector/insert) Самая полезная из них — для вставки диапазона: `v.insert(v.begin() + 1, src.begin(), src.end())`. Метод возвращает итератор на вставленный элемент.
- `pop_back()` — удаляет последний элемент.
- `erase()` — удаляет один или несколько элементов. Вызов `v.erase(it)` удалит элемент, на который указывает итератор `it`. А `v.erase(it_start, it_end)` удалит элементы в диапазоне. У метода несколько [перегрузок.](https://en.cppreference.com/w/cpp/container/vector/erase) Метод возвращает итератор за последним удалённым элементом.
- `clear()` — удаляет все элементы.
```cpp {.example_for_playground .example_for_playground_003}
std::vector<std::string> column_names = {"id", "username", "date_joined"};
column_names.push_back("is_superuser");
column_names.insert(column_names.begin() + 1, "email");
for (std::string name: column_names)
std::print("{} ", name);
```
```
id email username date_joined is_superuser
```
Если говорить о внутренней реализации, то для вектора выделяется единая область памяти. В ней друг за другом хранятся элементы. При добавлении новых элементов этой памяти может не хватить. Тогда резервируется область большего объёма, и в неё переносятся все элементы. Чаще всего объём удваивается, но это зависит от реализации. {#block-vector-under-the-hood}
Метод `capacity()` показывает ёмкость вектора: сколько элементов в него вмещается, прежде чем требуется реаллокация.
Выделение нового блока памяти, перенос в него элементов и освобождение старого блока — это медленные операции. Их можно избежать, если максимальное количество элементов известно заранее. Для этого используется метод `reserve()`. Он принимает количество элементов и сразу выделяет память нужного объёма.
```cpp {.example_for_playground .example_for_playground_004}
std::vector<int> data;
std::println("size: {}, capacity: {}", data.size(), data.capacity());
data = {10, 20, 30, 40, 50};
std::println("size: {}, capacity: {}", data.size(), data.capacity());
data.reserve(1'000);
std::println("size: {}, capacity: {}", data.size(), data.capacity());
```
```
size: 0, capacity: 0
size: 5, capacity: 5
size: 5, capacity: 1000
```
Реализуйте функцию `merge()`, которая принимает два отсортированных по возрастанию вектора. Функция возвращает вектор, содержащий элементы первого и второго векторов с сохранением отсортированности. {.task_text}
Например, для векторов `1, 3, 3, 7` и `0, 1, 3, 4` функция должна вернуть вектор `0, 1, 1, 3, 3, 3, 4, 7`. {.task_text}
Если вам нужно уточнить информацию о методах контейнера, воспользуйтесь [cppreference.](https://en.cppreference.com/w/cpp/container/vector) Не стесняйтесь подглядывать туда при решении задач. {.task_text}
```cpp {.task_source #cpp_chapter_0072_task_0020}
std::vector<int> merge(std::vector<int> v_left, std::vector<int> v_right)
{
}
```
Перемещайтесь по обоим векторам и в каждый момент времени сравнивайте пару элементов из `v_left` и `v_right`. Если элемент из `v_left` меньше, добавляйте его в результирующий вектор и сдвигайте итератор по `v_left` вперёд. Иначе добавляйте в результирующий вектор значение из `v_right` и перемещайте вперёд итератор по этому вектору. {.task_hint}
```cpp {.task_answer}
std::vector<int> merge(std::vector<int> v_left, std::vector<int> v_right)
{
std::vector<int> res;
auto it_l = v_left.cbegin();
auto it_r = v_right.cbegin();
while (it_l != v_left.cend() || it_r != v_right.cend())
{
if (it_r == v_right.cend() || (it_l != v_left.cend() && *it_l < *it_r))
{
res.push_back(*it_l);
++it_l;
}
else if (it_r != v_right.cend())
{
res.push_back(*it_r);
++it_r;
}
}
return res;
}
```
## Класс array
Итак, для большинства задач подходит динамический массив [std::vector](https://en.cppreference.com/w/cpp/container/vector). Но если количество элементов известно и неизменно, выбирайте статический массив [std::array](https://en.cppreference.com/w/cpp/container/array). Он занимает меньше места, чем вектор.
Тип и количество элементов — это параметры шаблона массива.
```cpp
template<class T, std::size_t N>
struct array
{
// Реализация
};
```
Создание массива из 4-х элементов типа `double`:
```cpp
std::array<double, 4> interpolated_data = {77.0, 77.2, 76.99, 77.3};
```
Реализуйте шаблонную функцию `is_diagonal()`. Она принимает квадратную матрицу, реализованную как массив массивов. {.task_text}
Функция возвращает `true`, если матрица является [диагональной.](https://ru.wikipedia.org/wiki/%D0%94%D0%B8%D0%B0%D0%B3%D0%BE%D0%BD%D0%B0%D0%BB%D1%8C%D0%BD%D0%B0%D1%8F_%D0%BC%D0%B0%D1%82%D1%80%D0%B8%D1%86%D0%B0) В такой матрице все элементы вне главной диагонали равны нулю. Например: {.task_text}
```
5 0 0
0 -1 0
0 0 2
```
```cpp {.task_source #cpp_chapter_0072_task_0060}
template<std::size_t N>
bool is_diagonal(std::array<std::array<int, N>, N> matrix)
{
}
```
Главная диагональ матрицы состоит из элементов с одинаковыми индексами: `matrix[0][0]`, `matrix[1][1]` и так далее. {.task_hint}
```cpp {.task_answer}
template<std::size_t N>
bool is_diagonal(std::array<std::array<int, N>, N> matrix)
{
for(std::size_t i = 0; i < matrix.size(); ++i)
{
for (std::size_t j = 0; j < matrix[i].size(); ++j)
{
if (i == j)
continue;
if (matrix[i][j] != 0)
return false;
}
}
return true;
}
```
## Абстрактные типы данных и структуры данных
Когда речь заходит о контейнерах сложнее вектора, важно отличать эти два понятия.
Абстрактный тип данных (АТД) — это «чёрный ящик», умеющий выполнять над набором элементов заданный перечень операций. Он никак не задаёт реализацию этих операций.
Структура данных, наоборот, определяет, как элементы хранятся в памяти и как именно реализованы операции.
В некотором роде АТД — это интерфейс, в то время как структура данных (или их комбинация) ложится в основу конкретной реализации этого интерфейса.
Зачастую у АТД, реализующей его структуры данных и конкретного класса в языке программирования совпадают названия. Так, класс C++ `deque` — это реализация одноимённого АТД «Дек».
## Класс deque
Если ожидаются частые вставки в начало и конец контейнера, присмотритесь к классу [std::deque](https://en.cppreference.com/w/cpp/container/deque) (double-ended queue, двунаправленная очередь). Он реализует [абстрактный тип данных «Дек».](https://en.wikipedia.org/wiki/Double-ended_queue)
Реализация дека в C++ поддерживает обращение к элементам по индексу. Этим он схож с массивами `std::vector` и `std::array`. Но у него есть важное отличие. Оно заключается в способе размещения элементов в памяти. Элементы массивов хранятся в памяти непрерывно, а элементы дека — кусочно-непрерывно.
В большинстве реализаций под элементы дека выделяется _набор_ массивов фиксированной длины. Они могут располагаться в совершенно разных участках памяти. Поэтому заводится дополнительный контейнер, хранящий адрес каждого из массивов. Зная индекс элемента в деке и длину массива, легко вычислить, где именно этот элемент расположен.
Заведем дек `d` и поработаем с ним:
```cpp {.example_for_playground .example_for_playground_005}
std::deque<int> d = {7, 6, 2, 0, 3, 9, 0, 1, 5, 3, 5, 5};
std::println(" {}", d); // Пробелы для отступа слева
d.push_front(4);
d.push_back(8);
d.push_back(3);
std::println("{}", d);
```
```
[7, 6, 2, 0, 3, 9, 0, 1, 5, 3, 5, 5]
[4, 7, 6, 2, 0, 3, 9, 0, 1, 5, 3, 5, 5, 8, 3]
```
Если допустить, что выделяемые под дек массивы содержат по 6 элементов, дек `d` можно представить так:
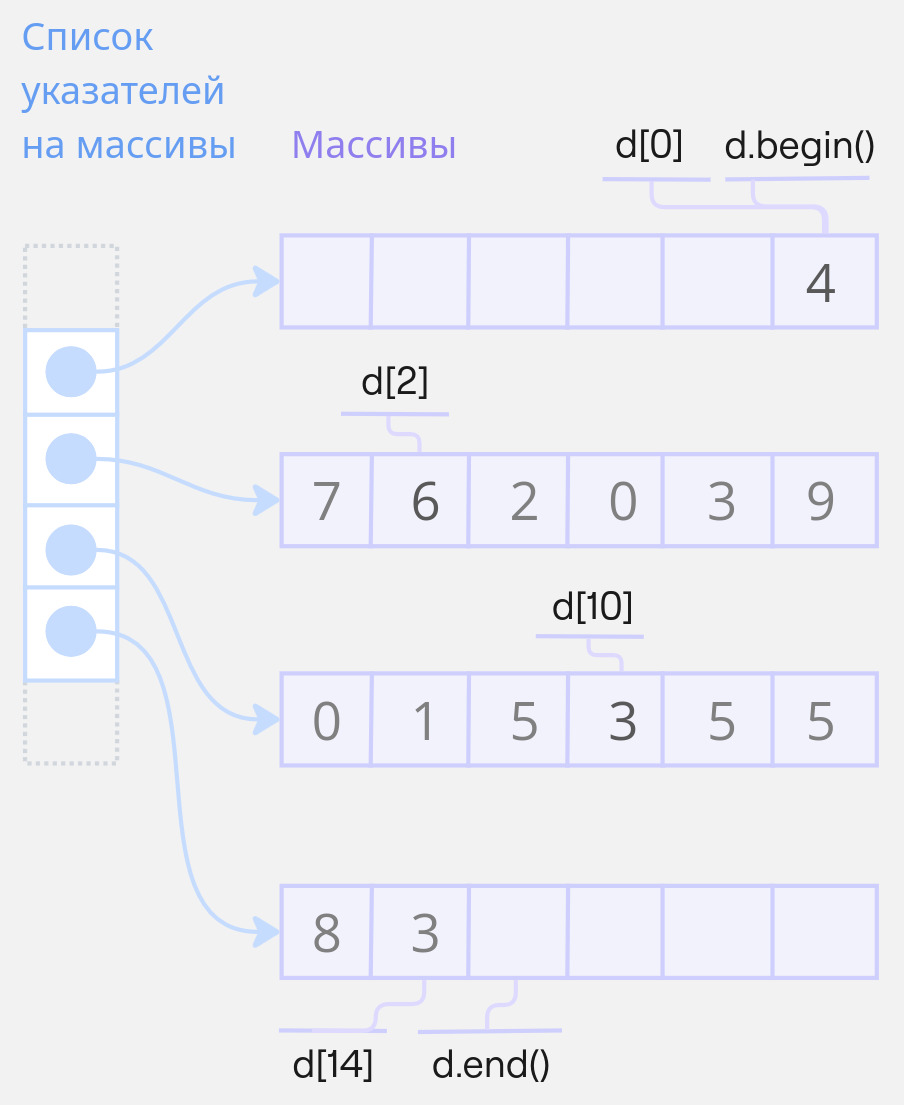 {.illustration}
Многие разработчики считают дек чем-то экзотическим и никогда его не используют. На самом деле периодически попадаются задачи, для которых он отлично подходит. Рассмотрим один такой пример.
[Work stealing](https://en.wikipedia.org/wiki/Work_stealing) — это известная стратегия балансировки параллельных вычислений. Она описывает, как распределять потоки выполнения по ядрам процессора. Стратегия получила своё название из-за того, что простаивающие ядра перехватывают часть работы у загруженных. Каждому ядру соотносится дек потоков. Потоки могут удаляться с обоих концов дека. Стратегия work stealing реализована в асинхронном рантайме [Tokio](https://tokio.rs/) для Rust, фреймворке [Fork/Join](https://docs.oracle.com/javase/tutorial/essential/concurrency/forkjoin.html) для Java и библиотеке [Task Parallel Library](https://learn.microsoft.com/en-us/dotnet/standard/parallel-programming/task-parallel-library-tpl) для .NET.
А вот классическая задача с собеседований. Дан набор `numbers` из `n — 1` целых чисел. Каждое число принимает значение от `1` до `n` и встречается в наборе строго один раз. За исключением одного числа, отсутствующего в `numbers`. Найдите это число. {.task_text}
Например, вызов `get_missing({4, 1, 3, 5}, 5)` должен вернуть `2`. {.task_text}
Решите эту задачу с использованием [побитового оператора XOR](/courses/cpp/chapters/cpp_chapter_0023/#block-xor) `^`. Если не получается догадаться до решения, воспользуйтесь подсказкой. {.task_text}
```cpp {.task_source #cpp_chapter_0072_task_0040}
std::size_t get_missing(std::deque<std::size_t> numbers, std::size_t n)
{
}
```
Вспомните [таблицу истинности](/courses/cpp/chapters/cpp_chapter_0023/#block-xor) оператора XOR. Нас интересуют два его полезных свойства. 1) Если один из аргументов XOR — это `0`, то второй является результатом: `x ^ 0 == x`. 2) Если аргументы XOR совпадают, то результат всегда равен `0`: `x ^ x == 0`. Эти свойства ведут к интересному следствию. Из последовательности операций XOR `a ^ b ^ c ^ ... ^ n` можно убрать все пары одинаковых чисел, и это не изменит результат! Ведь `a ^ a` — это `0`, а `b ^ 0` — это `b`. Значит, задача решается двумя циклами. В первом цикле мы находим результат применения XOR ко всем числам от `1` до `n`. Во втором цикле мы последовательно применяем XOR к получившемуся значению и каждому числу набора `numbers`. Результатом будет отсутствующее в `numbers` число. {.task_hint}
```cpp {.task_answer}
std::size_t get_missing(std::deque<std::size_t> numbers, std::size_t n)
{
std::size_t res = 0;
for(std::size_t i = 1; i <= n; ++i)
res ^= i;
for(std::size_t n: numbers)
res^= n;
return res;
}
```
## Классы list и forward_list
Доступ к элементам по индексу за `O(1)` — это ключевое свойство классов `std::array`, `std::vector` и `std::deque`. Но вставка и удаление по произвольному индексу в них работают медленно: за `O(N)`. Ведь для этого нужно сдвинуть все элементы с бОльшим индексом. После чего итераторы на сдвинутые элементы инвалидируются. А добавление нового элемента в вектор может привести к перевыделению памяти и инвалидации всех итераторов. {#block-invalidation}
Списки `std::list` и `std::forward_list` устроены иначе. Их элементы находятся в разных участках памяти. При добавлении или удалении любого из них итераторы на остальные элементы остаются валидными. А вставка или удаление произвольного элемента работают быстро: за `O(1)`. При условии, что вы уже получили итератор на нужную позицию. {#block-list-it}
Итак, списки хороши для частых вставок и удалений из середины. Но они не поддерживают обращение по индексу: для получения N-ного элемента придётся перебрать все элементы перед ним.
Класс [std::list](https://en.cppreference.com/w/cpp/container/list) реализует [структуру данных «двусвязный список»](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D1%8F%D0%B7%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA#%D0%94%D0%B2%D1%83%D1%81%D0%B2%D1%8F%D0%B7%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_(%D0%B4%D0%B2%D1%83%D0%BD%D0%B0%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9_%D1%81%D0%B2%D1%8F%D0%B7%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA)) и поддерживает обход контейнера в обе стороны.
Класс [std::forward_list](https://en.cppreference.com/w/cpp/container/forward_list) реализует [односвязный список](https://ru.wikipedia.org/wiki/%D0%A1%D0%B2%D1%8F%D0%B7%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA#%D0%9E%D0%B4%D0%BD%D0%BE%D1%81%D0%B2%D1%8F%D0%B7%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA_(%D0%BE%D0%B4%D0%BD%D0%BE%D0%BD%D0%B0%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%BD%D1%8B%D0%B9_%D1%81%D0%B2%D1%8F%D0%B7%D0%BD%D1%8B%D0%B9_%D1%81%D0%BF%D0%B8%D1%81%D0%BE%D0%BA)) и поддерживает обход только от начала к концу.
Как вы [помните,](/courses/cpp/chapters/cpp_chapter_0061/#block-iterator-categories) итераторы в C++ делятся на несколько категорий. {.task_text}
Как считаете, к какой из них относятся итераторы по `std::forward_list`? Напишите `random access`, `bidirectional` или `forward`. {.task_text}
```consoleoutput {.task_source #cpp_chapter_0072_task_0090}
```
В односвязном списке можно перебирать элементы только от начала к концу. {.task_hint}
```cpp {.task_answer}
forward
```
Реализуйте функцию `get_equator()`. Она принимает односвязный список и возвращает значение элемента, стоящего на экваторе. {.task_text}
Экватор — это последний элемент в списке, сумма элементов _до_ которого меньше суммы элементов _после._ Значение самого элемента в обеих суммах не учитывается. Для первого элемента сумму элементов _до_ считаем равной 0. Для последнего элемента сумму элементов _после_ тоже считаем равной 0. {.task_text}
Считаем, что список состоит минимум из двух элементов и содержит только положительные числа. {.task_text}
Примеры: {.task_text}
- Список: `5 -> 2 -> 4 -> 8 -> 1`. Результат: 4. Сумма элементов `5, 2` меньше суммы элементов `8, 1`. Сумма `5, 2, 4` уже больше значения `1`.
- Список: `100 -> 50 -> 25 -> 12`. Результат: 100. Это единственный элемент, для которого сумма _до_ меньше суммы _после._
```cpp {.task_source #cpp_chapter_0072_task_0030}
int get_equator(std::forward_list<int> lst)
{
}
```
Посчитайте сумму `sum` всех элементов списка. Примите за значение экватора первый элемент списка: `equator = list.front()`. Затем пройдитесь по списку и для каждого элемента вычислите сумму элементов _до_ `sum_left` и сумму элементов _после_ `sum_right`. Значение `sum_left` вначале равно нулю и накапливается. Значение `sum_right` вычисляется как `sum - sum_left - val`, где `val` — текущий элемент. Если `sum_left` меньше `sum_right`, то экватор приравнивается текущему элементу. {.task_hint}
```cpp {.task_answer}
int get_equator(std::forward_list<int> list)
{
int sum = 0;
for(int val: list)
sum += val;
int sum_left = 0;
int equator = list.front();
for(int val: list)
{
const int sum_right = sum - sum_left - val;
if(sum_left < sum_right)
equator = val;
sum_left += val;
}
return equator;
}
```
----------
## Резюме
Алгоритмическая сложность работы с последовательными контейнерами:
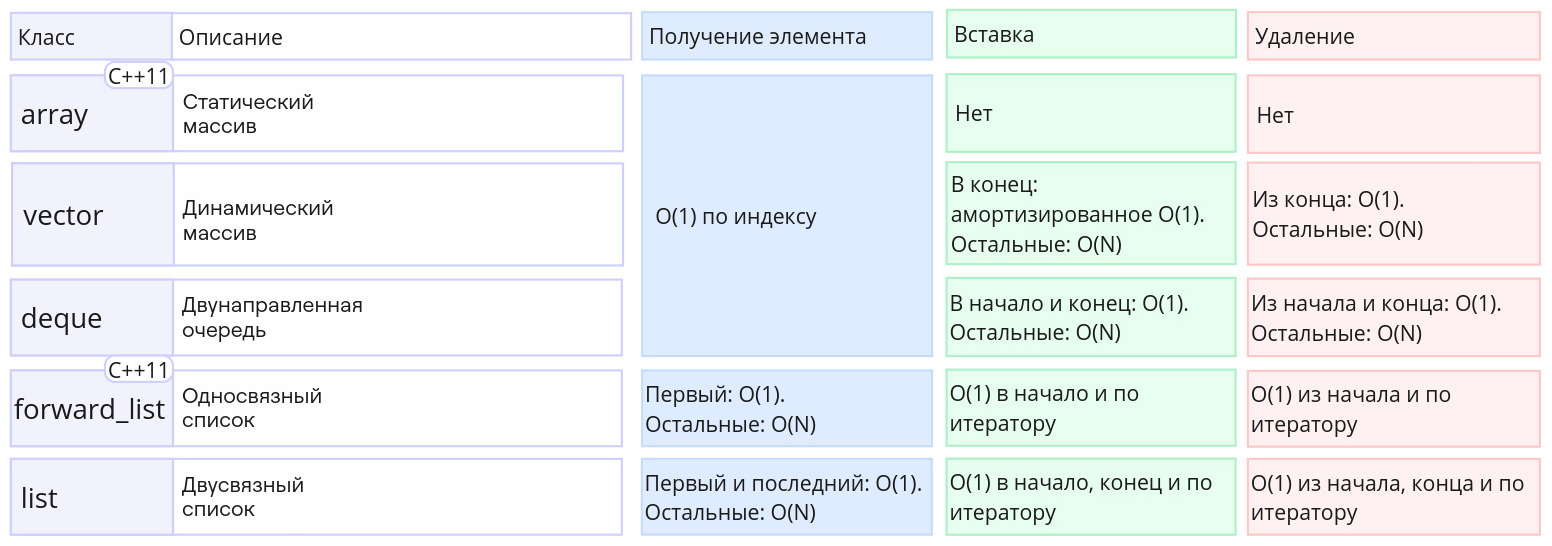 {.illustration}
Кстати, алгоритмическая сложность операций над строкой `std::string` такая же, как над вектором: их внутреннее устройство схоже.
Наша группа в telegram. Здесь можно задавать вопросы и общаться.
Задонатить. Если вам нравится курс, вы можете поддержать развитие площадки!